
Over the last few years, I have worked on over a dozen projects at MarkLogic, both as a consultant and as a pre-sales engineer. I have been surprised at how some projects seem to go quickly and others seem to get bogged down. The primary reason for delays is older RDBMS systems fail to produce high-quality document data. Looking back on these projects, I see a direct correlation between speed of MarkLogic projects and the use of an important integration pattern: the Load As Is Integration Pattern.
While I see many well-intentioned projects try to build document transformation tools on systems like Hadoop, MapReduce, HBase and Java, most of these frameworks take a long time to build, test and optimize simply because they were not originally designed to transform and validate JSON and XML documents. Using MarkLogic to transform and validate these documents really is using the right tool for the right job. Let me explain what the Load As Is pattern is and why it accelerates MarkLogic projects.
What Is the Load As Is Pattern?
What I am going to introduce is how you can clean on the fly — while building. In this piece, I am going to make the assumption that you have worked with document stores, and understand the structure of XML and JSON (here’s a great refresher if you need it).
The Load As Is Integration Pattern is likely the biggest departure when working with MarkLogic — and the most difficult concept for people to wrap their heads around. As it sounds, the pattern is the process of loading data from external data sources directly into MarkLogic with minimal change to the source data format.
Not Just a Data Dumping Ground
The first thing I want to dispel is that you are just dumping data into a data store. Maybe that is how some document databases work — but MarkLogic actually creates a schema-agnostic (but schema aware!) Universal Index on the fly. So as data is being ingested, a Universal Index is being created. And the Universal Index is not one index — but a compilation of dozens — which you can control to increase speed. The Universal Index uses labels and tags within documents to quickly index new data without the need for any up-front data modeling. I’ll get into more about the Universal Index in a moment.
The key concept to understand — and accept — is that all data does not have to be cleaned up front. That is not to say structure and data hygiene is not important, it is simply saying we are changing the order in which you do it. The advantage? By cleaning only the data you need — as you need it — you can demonstrate far greater agility than your brethren building on relational systems. Let me show you.
When Is the Load As Is Pattern Used?
The Load As Is pattern is used in the initial stages of many MarkLogic projects. It is used whenever we need to load new data into MarkLogic from an external data source. This is often the first step in building a new application or adding new data to an existing application. The Load As Is pattern is widely used by experienced MarkLogic consultants, database administrators, and business analysts who are trying to quickly grasp the structure and quality of any new data set.
A diagram of the Load As Is pattern and the external transform anti-pattern is shown in Figure 1.

Figure 1: This figure compares the low-cost Load As Is pattern vs. the high-cost anti-pattern of using 3rd-Party data transformation tools. These external tools can’t use the MarkLogic Universal Index to analyze data.
The Load As Is pattern is typically used when loading new data from any other data source. This data could be complex relational data, data from external XML or JSON documents, graphs, CSV files or even Microsoft documents or spreadsheets.
Advantages of the Load As Is Pattern
MarkLogic customers find the Load As Is pattern has lower costs and provides higher agility than the alternative pattern of using third-party data transformation tools to convert data into proper data formats before loading into MarkLogic. The Load As Is pattern is also the first stage in many Data Hub architectures that are used to break down data silos.
The direct Load As Is pattern provides many advantages over other more indirect approaches including:
- Fast Data Analysis and Data Profiling
- Continuous Content Enrichment
- Integrated Document Validation
- Integrated Data Quality
- Automated Model Generation and Schema Inference
I’m going to touch on all five advantages.
Fast Data Analysis Using Universal Indexes
As I mentioned, as soon as data is loaded into MarkLogic, it is immediately indexed using MarkLogic’s Universal Indexing system. This means each data element can be quickly analyzed using simple queries and data profiling tools. A simple query can determine, for example, if 10,000 random PersonBirthDate elements are cast as valid date structures for sorting results by date. Figure 2 shows an image of the MarkLogic Data Analyzer tool, which makes this process quick and easy.
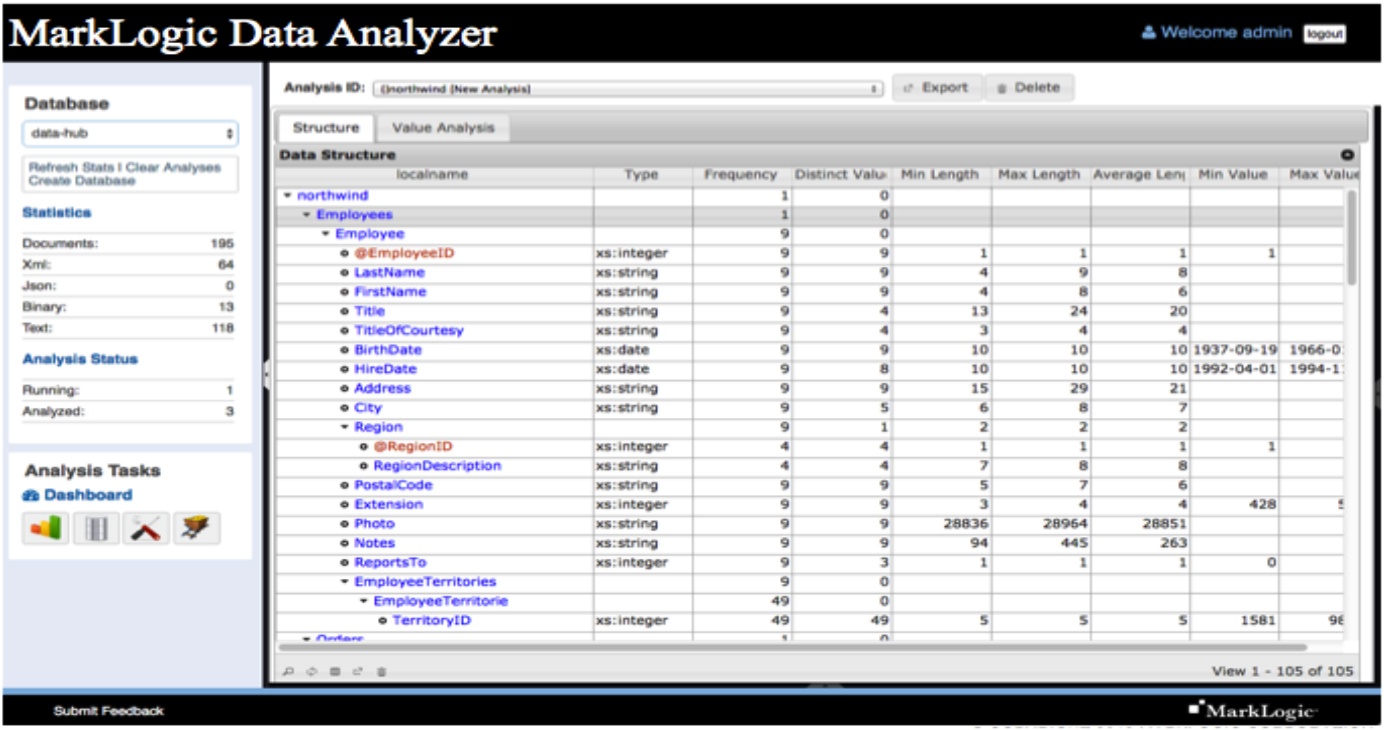
Figure 2: Screen image of the MarkLogic Data Analyzer. Using the Universal Index, analysis can be performed within minutes after data loading.
MarkLogic Consulting Services has built a MarkLogic Data Analyzer, that allow us to quickly and automatically generate detailed data profile information on each data element within documents using data sampling and data type inference. Data profiles show inferred data types (strings, integers, dates etc.), enumerated values (codes) and patterns that can be used to validate formats. Because of the MarkLogic Universal Index, data profiling can be run on samples of data or even entire large data sets within minutes of loading into MarkLogic.
MarkLogic Data Analyzer and other query tools do a deep analysis of each individual data element with documents. For example, if you have a data element such as <PersonFamilyName>, the data analyzer will tell you the data type (a string) and what the statistics of this string are. This statistical profile data might include:
- Minimum string length
- Maximum string length
- Average string lengths (average, mean, modes)
- Standard deviation of string lengths
- Characters used (all letters, no digits)
- Frequency of empty data elements
Why is this data important? What if we are loading this data into a structure where the <PersonFamilyName> was a required field? If half the last names were empty, then this data might either be corrupt or just might not be very useful. Too often we make assumptions that our data is clean — and don’t find out until a project is well underway that the data we hoped to use does not have enough data quality for our projects. The MarkLogic Universal Index and the Load As Is pattern become our first defense against corrupt and poor quality data.
Continuous Content Enrichment
Once data has been profiled it can then be continuously enriched using a set of powerful transaction-safe data transformation tools that are built directly into MarkLogic. These transformation tools use both the universal indexes as well as caching and distributed query processing to rapidly transform documents into structures that allow for transactions, search, and analytics. Continuous Content Enrichment of data within MarkLogic is also one of the core Integration Patterns used by experienced MarkLogic integration teams.
As the name implies, Continuous Content Enrichment is not a one-time operation. As data is used for new purposes it can be continuously updated with new data elements without disrupting the flow of information into or out of MarkLogic. If you have 15 minutes, here’s a tutorial on CoRB, a Java tool designed for bulk content-reprocessing of documents stored in MarkLogic and a tutorial on Progressive Transformation Using the Envelope Pattern.
A diagram of the “Content Enrichment” pattern is shown in Figure 3.

Figure 3: The Content Enrichment Pattern takes from the Enterprise Integration Patterns web site.
Content enrichment is the conversion of numeric codes into human-readable strings. For example, a person’s gender code might be 1 for “Female” and 2 for “Male.” Only the applications that run on top of the RDBMS understand how to use reference data to convert the codes from numeric to human-readable labels.

Figure 4: Sample data before and after content enrichment.
These enriched labels also make search tools easier to build and easier to use. So in a case in which a user enters “Female physicians” into a healthcare provider search tool, the universal index will rank female physicians higher than male physicians in the results. Note that enrichment has not removed the original source codes. It merely allows scripts to be run to update labels if the label text is changed.
Looking up numeric codes and adding the English language labels (or any other language labels) is something that MarkLogic is very good at doing. Code lookup tables are usually small so they don’t take up much memory. A typical conversion of raw RDBMS data to a human-readable document may require dozens of lookups. MarkLogic allows you to use in-memory key-value maps to make these lookups fast.
Other examples of content enrichment include verification of US Postal Address standards and adding geocoding elements such as longitude and latitude for fast geo-searching. These elements allow combined queries such as “find all female physicians within 10 miles of my home.”
Our next step is to understand if the results of our enrichments can pass a series of tests for data quality. These tests are critical if our raw-data loaded into MarkLogic can be used in a production setting.
Integrated Document Validation
We now ask the question,”How do I know if the documents produced as a result of the Continuous Content Enrichment process conform to a clear set of business rules?” These rules help us understand if any given document will pass the key data quality tests, including the existence of all required data elements, data element ordering and the data types of each leaf element in our document tree-structure.
Unlike most relational databases, UNIX or Hadoop files or simple file systems, MarkLogic allows each database to be configured with its own unique schema rules database. The MarkLogic Schema database is used to store multiple types of business rules to perform tasks such as document consistency and validation. A diagram of document validation is provided in figure 5.

Figure 5: Document validation is used by binding a namespace in an XML instance document with the appropriate XML Schema.
Typically, enrichment-transformation cycles are repeated until documents achieve the minimal criteria required by a business function. They are then validated against a canonical XML Schema and the results of this process are stored in specialized metadata properties that are integrated directly into the MarkLogic documents. An example of an XML Schema diagram is shown in Figure 6.
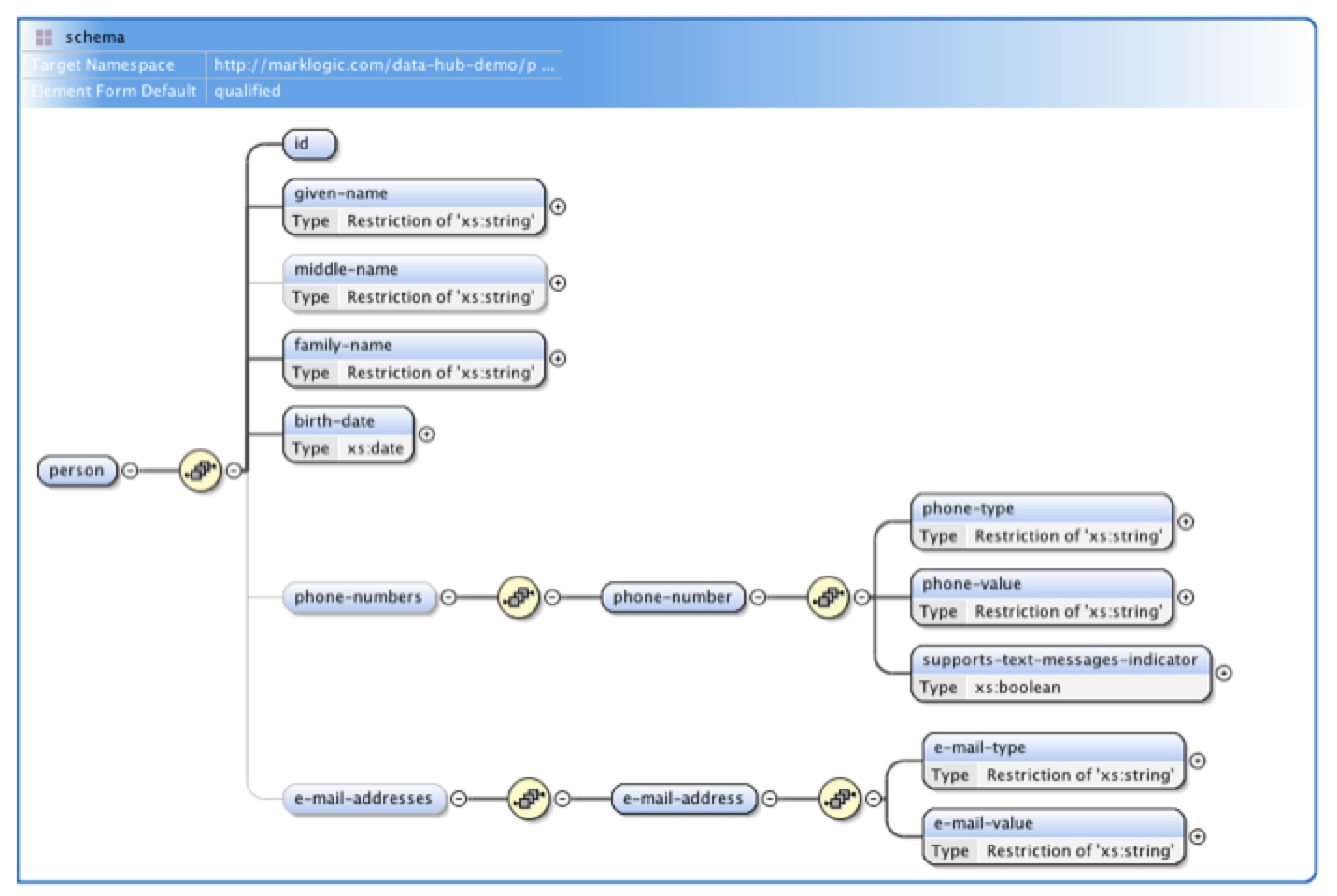
Figure 6: Sample of graphical design view of a typical XML Schema file using oXygen XML editor. Note that the light gray lines mark middle-name, phone numbers and e-mail address as optional data elements.
XML Schema validation is a mature technology that has been a best practice in document stores for over ten years. Although the exact methods of how fast XML Schema validation works is complex, graphical editors make it easy for non-programmers to create and view validation rules. These rules are captured in an XML Schema file (called the .xsd file) and stored directly within the MarkLogic Schema database.
Each XML document and XML Schema can be associated with a string called a namespace. Because both documents and the XML Schemas both reference the same namespace, MarkLogic knows precisely what rules to apply to each data element. Any variation from these rules can quickly trigger exceptions that can be detected by data quality checks.
Note that MarkLogic provides tools so that even simple JSON documents can also be quickly converted into rich XML forms with namespaces for complex, yet precise validation.
XML Schema validation is only one tool to allow you to manage data quality checks. Other queries that leverage the universal index can also be created to verify complex business rules like whether the total of an order is equal to the sum of the line items.
Now that we have a good understanding of these data quality testing tools, we can understand how the Load As Is pattern accelerates the process of getting our data into shape. Although the result of validation can return many specific errors, many data quality systems represent the result of document validation as a Boolean variable: a DocumentValidIndicator is either TRUE or FALSE. There is no gray middle ground. The next section describes how MarkLogic can be much more flexible than this black and white check.
Integrated Data Quality Metrics
As you become more familiar with the power of MarkLogic’s Universal Index and Integrated Validation tools you may ask:
- How do I put all these things together to make a decision about when to call my data “production ready”?
- What if I have valuable data that is not yet 100% valid but I still want to include them in my search results?
- What if I want to change the ranking of search based on data quality?
You will be happy to know that MarkLogic does all of this for you.
MarkLogic can associate a data quality score, typically an integer value from 1 to 100, with every document. These scores are then used to determine whether the documents should be tagged as “ready for search” or even how the search results should be ordered. Organizations can use MarkLogic built-in document metadata property structures to associate one or more data-quality components that contribute to an overall document quality score. The Load As Is pattern is critical to rapid advancement to strong data quality metrics.
Figure 7 shows examples of XQuery code to insert documents with an initial data quality of 50. It then shows how this document might have its data quality upgraded to 70 after enrichments. The final query shows how all documents above a threshold of 60 might be included in search results.

Figure 7: Sample queries to set and get data quality as well as to only return nodes with quality scores above a threshold such as 60.
Automated Model Generation and Schema Inference
The Load As Is pattern and its ability to immediately analyze documents, permits queries to be written that allow you to rapidly create accurate document models of your raw data, enrich the data and validate the documents against your XML Schema. There are still some cases, however, where users don’t have either the time or expertise to build an XML Schema. For those situations, there are desktop tools that automatically generate the validation rules directly from your rough-cut data.
The process of generating rules from data is called “Model Generation.” Software can analyze many examples of your data and look for patterns and variability. These tools can also generate sample XML data if you already have the XML Schema. They are ideal for building unit tests for your validation frameworks. Figure 8 shows a sample of the circular continuous data quality improvement workflow of a typical ingest, model, refine and test.

Figure 8: Examples of cycles of Load As Is including document analysis, schema generation, enrichment and scoring.
MarkLogic also works with document-oriented desktop Integrated Development Environments such as oXygen XML Editor so that XML Schemas can be quickly generated directly from sample data sets. No prior experience with the XML Schema formats is needed. A typical data ingestion workflow might provide both initial validations of raw “staging” data as well as validation of the results of data enrichment after transformations are done. Once documents reach an acceptable score, the instance documents can be used to automatically generate full XML Schema models of the documents. These high-quality models are sometimes called “canonical” models. These canonical models can then be queried directly. For example, the XML Schema will contain a list of all possible values (enumerations) of specific data elements such as PersonGenderCode. The queries of these models can be used as selection lists for web-based GUI editors. XML Schemas can then be used to generate “templates” that serve as the basis for template-style transforms.
These five areas are just a sample of the advantages of using the Load As Is pattern within MarkLogic. There are also many ongoing MarkLogic projects underway to make the Load As Is pattern even more central to the rapid and cost-effective creation of Enterprise Data Hub projects. These ongoing projects will continue to make MarkLogic the most cost-effective system for breaking down data silos and building integrated views of customers.
Dan McCreary
View all posts from Dan McCreary on the Progress blog. Connect with us about all things application development and deployment, data integration and digital business.
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Secure File Transfer
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites