Using the UML-to-Entity Services Toolkit for UML Modeling with Data Hub and Semantics

Previous Posts: Part 1: How to Model and Manage Entities with UML Part 2: Introduction to the UML-to-Entity Services Toolkit: UML Modeling with MarkLogic’s Entity Services
Welcome to the continuation (i.e., the third blog) of my series that explores modeling for MarkLogic’s Entity Services using the Unified Modeling Language (UML). In Part 1, I introduce the concept of using UML notation to visually depict the model and explain how to seamlessly transform the UML model to MarkLogic’s Entity Services model descriptor format, which I demonstrate in Part 2 using movies an example, and also introduce my UML-to-Entity Services toolkit for model-driven MarkLogic development.
Here, we will examine modeling for a mixed document/semantic database. Besides showcasing semantics, my example also demonstrates how to use UML modeling with MarkLogic’s Data Hub Framework (DHF). The source code for this UML modeling example is on GitHub.
Overview of the Employee-Department Data Model Using Semantics
Our data model (Figure 1) describes employees and departments in a company’s human resources repository. The company is the fictional GlobalCorp. Our model is based on an example included in DHF’s GitHub repository.
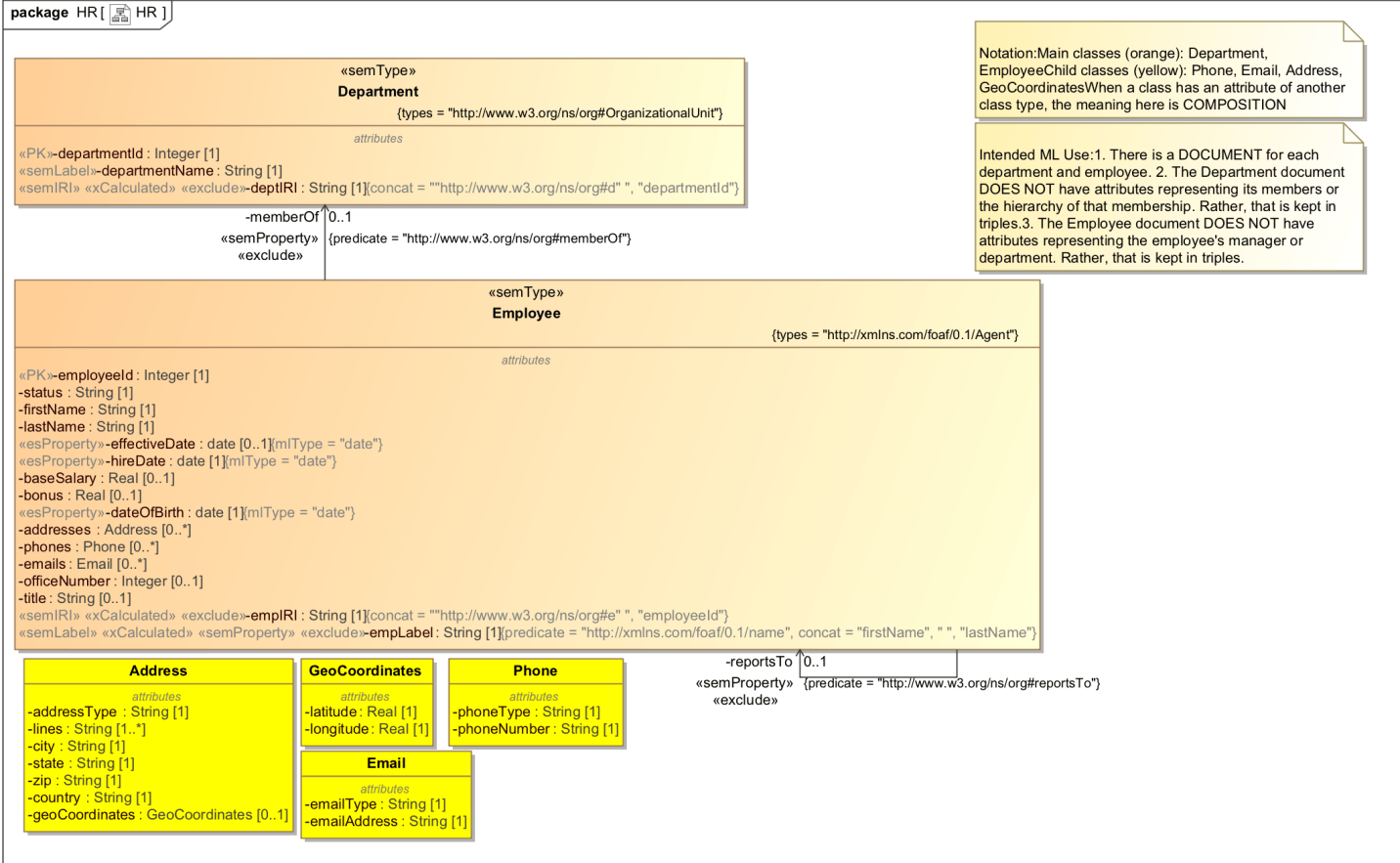
Figure 1: Sample data model with departments and employees
The two main classes are Department and Employee. A department has an ID (departmentId) and a name (departmentName). An employee has an ID (employeeId), name (firstName, lastName), salary (baseSalary, bonus), hire status and dates (status, effectiveDate, hireDate, title), plus addresses, phone numbers, and emails. The latter are complex types, hence the four additional classes—Address, Phone, Email, GeoCoordinates (a type within Address)—which are datatypes used by Employee.
Relationships are particularly significant in this example; for example, an employee reportsTo another employee and an employee is a memberOf a department. We might physically represent these relationships by using document references or containment. The employee document, for example, could contain an attribute called memberOf, whose value is the ID of the corresponding department. However, GlobalCorp has decided to represent these relationships using semantic triples instead for the following reasons:
- Since reporting structures and department memberships change frequently, GlobalCorp prefers to keep the representation of these relationships soft and maintain current relationships by updating triples than by re-routing document references.
- GlobalCorp recently acquired rival firm ACME and has decided to use the standard W3C organizational ontology to represent that merger semantically. Having already started down the semantic road, GlobalCorp has decided to use the same ontology to represent human resource relationships.
- GlobalCorp realizes the potential of SPARQL to run powerful human resource queries, such as the ability to build an organizational reporting tree without having to traverse employee documents.
If you look carefully at the model, you will see it is peppered with semantic, or “sem”, stereotypes. The model makes use of the Entity Services UML profile included in the toolkit. The profile defines semantic and other stereotypes used to map UML to Entity Services. Using these stereotypes, GlobalCorp is able to describe in the model the IRIs, RDF types, and RDFS labels of employees and departments. It also relates these entities using predicates defined by the W3 organizational ontology.
Here is a breakdown of the semantic stereotypes used in GlobalCorp’s model:
- semType stereotype: Both
DepartmentandEmployeeclasses bear the stereotypesemType. This stereotype associates with each class an RDF semantic type. Department’s RDF type is https://www.w3.org/ns/org#OrganizationalUnit. Thus, from a semantic perspective, a department is an organizational unit as defined by W3C’s organization definition. Employee’s RDF type is friend-of-a-friend (FOAF) ontology. - IRI definitions: The
DepartmentandEmployeeclasses also define an IRI. The purpose of the IRI is to uniquely identify a department or employee when we use it as the subject or object for a semantic triple. In each class we nominate one attribute to serve as the IRI, stereotyping that attribute assemIRI. ForDepartment, that attribute isdeptIRIofDepartment; forEmployee, it isempIRI. Notice that each of the IRI attributes also bears the stereotypesxCalculatedandexclude. Thus, these IRI attributes are merely calculated fields, used to help construct triples. That attribute will not be included in the XML document representation of the department or employee. Theconcattag indicates how the IRI’s value is calculated. For exampledeptIRIis the concatenation of “http://www.w3.org/ns/org#d” and the department ID. - RDFS labels: Each class also defines an RDFS label. In semantics, it is a good practice to associate a user-friendly label with the IRI . As with IRI, we nominate one attribute in each class to serve as the label; we stereotype it as
semLabel. ForDepartmentthat attribute isdepartmentName. ForEmployee, it isempLabel. Notice thatdepartmentNameis not a calculated field; it is a full-fledged attribute that will also appear in the department’s XML document.empLabel, on the other hand, is an excluded field whose value is calculated from thefirstNameandlastNameattributes. - Employee reportsTo Employee: The association shown as
reportsTo, which relates one employee to another, is asemPropertywith the predicate https://www.w3.org/ns/org#reportsTo. Thus if employee A reports to employee B, we construct a triple whose subject is the IRI of employee A (employee A’sempIRI), whose predicate is the one given, and whose object is the IRI of employee B (employee B’sempIRI). Notice theexcludestereotype; the XML representation of an employee will not contain thereportsToelement. We will maintain the relationship solely using a triple. - Employee memberOf Department: The association between
EmployeeandDepartmentshown asmemberOfis asemPropertywith predicate https://www.w3.org/ns/org#memberOf. The triple we create has the employee’sempIRIas subject, the predicate given, and the department’sdeptIRIas object. This relationship is excluded from the document.
Specifying the stereotypes in the model is beneficial because the toolkit’s transform module, which maps the UML model to Entity Services, understands these semantic stereotypes and generates code to create triples based on the content of the document. For example, here in Figure 2 is the code the toolkit generates to create employee triples showing that every aspect of this code arises from the semantic stereotypes:
let $semIRI := map:get($options, "empIRI")
return (
sem:triple(sem:iri($semIRI), sem:iri("http://www.w3.org/2000/01/rdf-schema#label"), map:get($options, "empLabel")),
sem:triple(sem:iri($semIRI), sem:iri("http://www.w3.org/1999/02/22-rdf-syntax-ns#type"), sem:iri("http://xmlns.com/foaf/0.1/Agent")),
sem:triple(sem:iri($semIRI), sem:iri("http://www.w3.org/ns/org#memberOf"),sem:iri(map:get($options, "memberOf"))),
sem:triple(sem:iri($semIRI), sem:iri("http://www.w3.org/ns/org#reportsTo"),sem:iri(map:get($options, "reportsTo"))),
sem:triple(sem:iri($semIRI), sem:iri("http://xmlns.com/foaf/0.1/name"),map:get($options, "empLabel"))
)Figure 2: Auto-generated code creating triples based on semantic stereotypes
Figure 3 shows some example triples describing employee 114, his superior, and his department. He is a FOAF agent named Earl Garza who reports to Ruth Shaw (employee 1) and is a member of R&D (department 4).
| Subject | Object | Predicate |
| org#e114 | rdf:type | FOAF Agent |
| org#e114 | rdfs:label | “Earl Garza” |
| org#e114 | foaf/name | “Earl Garza” |
| org#e114 | org#reportsTo | org#e1 |
| org#e114 | org#memberOf | org#d4 |
| org#e1 | rdfs:label | “Ruth Shaw” |
| org#d1 | rdfs:label | “R&D” |
From UML Data Model to MarkLogic Data Hub
The MarkLogic Data Hub Framework provisions and supports two content databases: staging for initial or “raw” data and final for harmonized data. Once data is successfully ingested or loaded to the staging database, it can then be harmonized and transformed, and the harmonized form stored in the final database. Harmonized data is typically in a usable format that you want to serve queries and analytics.
GlobalCorp’s goal is to ingest its raw employee and department source data (as well as source data from ACME) into a MarkLogic Data Hub staging database, and then to harmonize that data into XML documents that conform to the UML model. Ingestion into the staging database is implemented by the batch import capability of MarkLogic Content Pump (MLCP). Subsequently, harmonization is a batch job that maps this raw data to the form governed by the UML model. As Figure 4 shows, through ingestion and harmonization the UML model is transformed to an Entity Services model. The harmonized documents are placed in the MarkLogic Data Hub’s final database. Documents in a MarkLogic Data Hub follow the envelope pattern. The content of the envelope is an XML representation of Employee and Department. The triples section of the envelope contains the semantic triples described above in Figure 3.
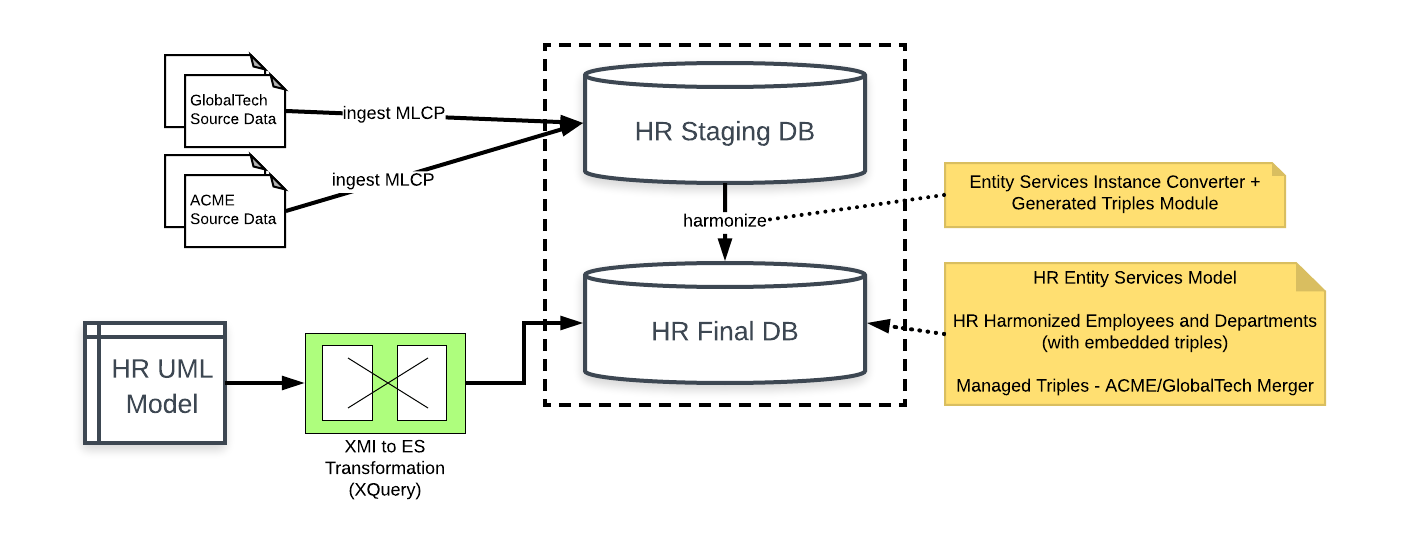 Figure 4: How the UML model and source data go into the final data hub
Figure 4: How the UML model and source data go into the final data hubIt is significant that the harmonization code is NOT written from scratch; most of it is, in fact, generated. The code to harmonize the XML content of the documents is generated by Entity Services based on the UML model. the model requires only minor tweaks to deal with source mappings. The code to generate the triples (Figure 2) is generated by the transform according to the semantic stereotypes included in the model.
Here is an excerpt Earl Garza’s harmonized employee envelope:
<envelope xmlns="http://marklogic.com/entity-services">
<headers>
<HRHeader xmlns="">
<lastHarmonizeTS>2018-04-12T05:53:34.957766-04:00</lastHarmonizeTS>
<entityType>employee</entityType>
<entitySource>global</entitySource>
<entityId>114</entityId>
<entityName>Earl Garza</entityName>
</HRHeader>
</headers>
<triples>
<sem:triple xmlns:sem="http://marklogic.com/semantics">
<sem:subject>http://www.w3.org/ns/org#e114</sem:subject>
<sem:predicate>http://www.w3.org/2000/01/rdf-schema#label</sem:predicate>
<sem:object datatype="http://www.w3.org/2001/XMLSchema#string">Earl Garza</sem:object>
</sem:triple>
<sem:triple xmlns:sem="http://marklogic.com/semantics">
<sem:subject>http://www.w3.org/ns/org#e114</sem:subject>
<sem:predicate>http://www.w3.org/1999/02/22-rdf-syntax-ns#type</sem:predicate>
<sem:object>http://xmlns.com/foaf/0.1/Agent</sem:object>
</sem:triple>
<sem:triple xmlns:sem="http://marklogic.com/semantics">
<sem:subject>http://www.w3.org/ns/org#e114</sem:subject>
<sem:predicate>http://www.w3.org/ns/org#memberOf</sem:predicate>
<sem:object>http://www.w3.org/ns/org#d4</sem:object>
</sem:triple>
<sem:triple xmlns:sem="http://marklogic.com/semantics">
<sem:subject>http://www.w3.org/ns/org#e114</sem:subject>
<sem:predicate>http://www.w3.org/ns/org#reportsTo</sem:predicate>
<sem:object>http://www.w3.org/ns/org#e1</sem:object>
</sem:triple>
<sem:triple xmlns:sem="http://marklogic.com/semantics">
<sem:subject>http://www.w3.org/ns/org#e114</sem:subject>
<sem:predicate>http://xmlns.com/foaf/0.1/name</sem:predicate>
<sem:object datatype="http://www.w3.org/2001/XMLSchema#string">Earl Garza</sem:object>
</sem:triple>
</triples>
<instance>
<Employee xmlns="">
<employeeId>114</employeeId>
<status>Active - Regular Non-Exempt (Part-time)</status>
<firstName>Earl</firstName>
<lastName>Garza</lastName>
<effectiveDate>2014-10-28-04:00</effectiveDate>
<hireDate>2013-01-14-04:00</hireDate>
<baseSalary>53120</baseSalary>
<bonus>7525</bonus>
<dateOfBirth>1969-04-27-04:00</dateOfBirth>
<officeNumber>767</officeNumber>
<title>Research Nurse</title>
<!-- for brevity, not showing addresses, phones, email -->
</Employee>
</instance>
</envelope>| Subject | Object | Predicate |
|---|---|---|
| org#Global | rdf:type | org#Organization |
| org#ACME | rdf:type | org#Organization |
| org#ACMETakeover | rdf:type | org#ChangeEvent |
| org#ACMETakeover | org:originalOrganization | org#ACME |
| org#ACMETakeover | org:resultingOrganization | org#Global |
Further Learning
To learn more about semantics and the MarkLogic Data Hub Framework, refer to the following resources:
Mike Havey
View all posts from Mike Havey on the Progress blog. Connect with us about all things application development and deployment, data integration and digital business.
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Security and Compliance
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites