Decimating Data Silos With Multi-Model Databases

A short time ago, I had a discussion with some architects working for one of the world’s largest health systems. They were interested in aggregating their myriad silos of medical registries (healthcare data) and wanted to accomplish this integration by converting all their data into more than 100 billion semantic triples. Here is what we proposed.
When I started on the project, the organization’s architects decided they would use semantic triples to relate petabytes of data across silos. There was no quibbling on their reasoning — but the trick was figuring out how. Hypothetically speaking, if their systems had 500 million records and 200 elements per record, the team would have ended up with 100 billion triples. This resulting data set would have been very hard to manage from a governance perspective (all the natural human understandable records would have been shredded), would not have performed well, and would probably have taken a long time to implement.
Once our team at MarkLogic understood the integration requirements, we suggested an architecture that would use a combined document and semantics model instead. The multi-model architecture would have a couple orders of magnitude less objects in the database. More specifically, it would only have 500 million documents and perhaps a similar amount of triples linking those documents. This combination architecture would perform much better, be more scaleable, be faster from a time-to-market perspective, and would provide better governance. Let’s take a closer look at what we proposed.
The Starting Point
As is typical with most healthcare organizations, this company had dozens if not hundreds of partially overlapping data silos. And like most companies, relied heavily on relational technologies for their transaction processing and data warehousing functions. Relational databases have been the mainstay of operational, transactional databases for the last 35 years. Their key characteristics include transactional integrity, high performance for small transactions, and reliability. Dimensional warehousing became popular for its ability to answer analytic queries on large amounts of data across multiple carefully crafted dimensions. Recently graph and document databases have become popular. Graph databases can easily represent and compute over relationships, whereas document databases have become popular because they naturally represent entities that naturally represent things in the real world.
The key problem with relational databases is that the data needs to be modeled up front quite extensively. As a result, organizations try to predict what data they need, how it relates to each other, and what questions they want the data to answer.
In this environment, we end up building application specific data silos and in this rapidly changing world, we invariably get it wrong. As we can see Figure 1 below, ETL and specific application-driven data sets are the key drivers of data silo proliferation for structured data sets. In fact, 60 percent of the cost of a new data warehousing project is allocated to ETL and corporations spend $36 billion annually on creating relational data silos. Then there are other silos that keep all the unstructured data as well. If we consider where all these data sets reside, we can easily get into the thousands of sources or data locations.
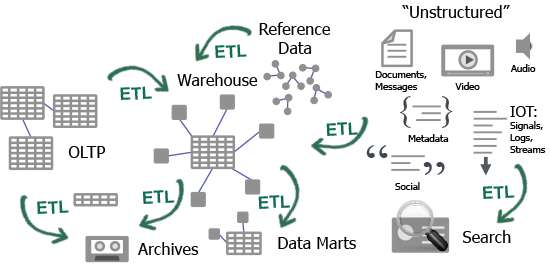
Figure 1. ETL and Data Silo Proliferation
Another way to look at the problem is that companies really want to have 360-degree views of all their business data, but what they have is either line of business data silos or technology data silos, as we can see in Figure 2 below, and LOTS of ETL to keep these silos in sync.
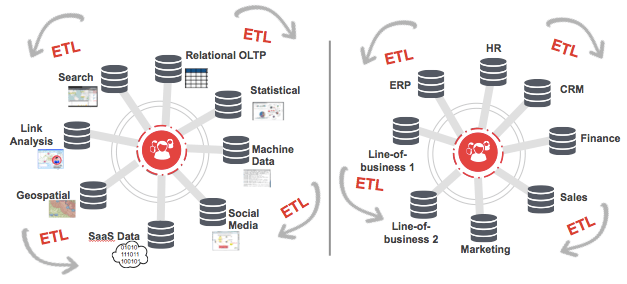
Figure 2. Business and technology silos don’t stay in sync without massive efforts.
What organizations need is a place that allows them to manage all their data in a schema-agnostic manner, relate all the data to each other via meaningful business concepts, and store it in a reliable and transactional manner. This place needs to enable organizations to “run the business” and “observe the business” without resorting to Extract, Transform, and Load. Think of it this way, as your data grows and grows and grows, you need to find a permanent home for it, otherwise you will spend all of your organization’s resources just moving data around between silos. This place is what we call an operational data hub (ODH).
Key Characteristics of Operational Data Hub
Most architects strive for a hub — but find themselves disappointed with the results. That’s because a good and effective operational data hub must be:
- Convergent: Operational & Analytical; Providing two-way interaction between data and users
- Contextual: Harmonizing data with semantic metadata
- Data-centric: Integrating at the data level — not just functional layer
- Cost-effective: Minimizing ETL, data copying, business silos, technical silos, and people-centric integration
- Secure: Providing a platform for rich data governance
- Complementary: Leveraging existing assets and patterns
Three Different Approaches to the ODH
I’ve mentioned the challenges with relational technology when creating an operational data hub (ODH) to eliminate data silos. Now I want to look at non-relational technology alternatives, and, keeping our characteristics above in mind, the pros and cons of three different architectural designs for an operational data hub:
- A semantics triple store/graph-only architecture
- A document store-only architecture
- A multi-model approach that combines a document store and triple store
1. Semantic RDF Triple Store/Graph-Only Approach
There are two different databases designed to store linked data: RDF Triple Stores and Graph databases. There are nuances between them. But as my colleague Matt Allen describes in this thread graph databases and RDF triple stores focus on the relationships between the data, often referred to as “linked data.” Data points are called nodes, and the relationship between one data point and another is called an edge. A web of nodes and edges can be put together into interesting visualizations — a defining characteristic of graph databases.
Designing an operational data hub with a “triple store-only” approach provides a very flexible way to link disparate data silos. The key benefits and concerns are summarized in below. Because a graph can model any relationship, you have unlimited flexibility in how the semantic triples are organized or queried. You can add new types and relationships easily at run-time. You can also query semantic triples via a standard well-defined query language, SPARQL. There are however some concerns with modeling all the ontology and content as semantic triples. While it makes sense to model the semantic concepts in an ontology as triples because that is their natural level of granularity, managing the content at this level brings some challenges.
In particular, the modeling must be done at a very low (element-by-element) level. Additionally, the original integrity of the documents is not maintained (similar to “shredding” that occurs in a normalized, relational database), making it very hard to manage data governance issues such as source lineage, software lineage, historical document updates, bitemporal information, security and rights management, and document deletion processing. In the healthcare example with a triple store-only approach, when a researcher queries for a particular cohort of patients, each patient’s content will be returned as hundreds (if not thousands) of triples all of which would need to be joined together to provide the patient context. This process would then need to be repeated for each patient in the cohort resulting in the need to perform millions or billions of joins, thereby creating a potential bottleneck and frustrating researchers.
Graph/RDF Triple Store-Only Approach Pros
- Unlimited flexibility –- model any structure
- Run-time definition of types & relationships
- Relate an entity to anything in any way
- Query relationship patterns
- Use standard query langugage –- SPARQL
- Create maximal context around data
Graph/RDF Triple Store-Only Approach Cons
- Hard to model at such a low level
- Hard to integrate with other systems
- Non-standard query languages and hard to hire expertise
- Need effective ways to join documents and handle similar but disparate semantic content
2. Document-Only Approach
Generally, because a document database is schema-agnostic, the fastest path to productivity is ingesting data “as-is” and then modeling based on desired outputs in an agile “just-in-time” fashion. Unlike relational data where the data determines the ideal normal form, we track more to the expected services and types of analytics.
The standard “ETL” (extract, transform, and load) is turned around to be “ELT” (extract, load, and transform as needed). With documents, you can persist datasets in the way they were ingested or the way they are naturally used. The goal of data modeling here is to identify application or enterprise-wide business-focused objects and model documents that naturally fit those objects. Here we can build human-oriented, intuitive models that are readable and understandable by non-technical users.
For example, using our healthcare model, if you show a patient-encounter document to someone, he or she will easily see that the root element labels the document as a patient encounter, that the encounter has a patient, a diagnosis, a treatment plan, a provider, a procedure, and so on. Additionally, the original context and integrity of the documents are maintained, making it very easy to manage data governance issues such as source lineage, software lineage, historical document updates, bitemporal information, security and rights management, and document deletion processing. Some key issues with natural documents are that they still need to be connected with, or joined to, other data and that different sources may have different labels for the same semantic content.
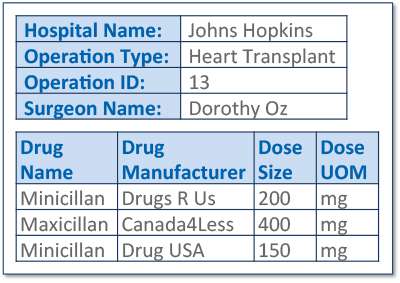
Document-Only Approach Pros
- Model the business exactly — without compromises
- Fast development
- Schema-agnostic, run-time designed, rich, JSON, XML and RDF data structures
- Queries everything in context
- Turns data into meaningful information
- Can query for relevance
Document-Only Approach Cons
- Defensive programming for unexpected data structures
- Expensive platforms,
- Immature tools
- Hard to hire expertise
3. Multi-model Semantics + Document Approach
With a multi-model approach using a document store and triple store to design an operational data hub, you get the best of both worlds: the natural human-understandable business objects models and the semantic conceptual human understandable relationships between those models. Data governance is simplified and joins between documents are intuitive and very fast.
Using a data platform such as MarkLogic to combine documents with semantics helps organizations rapidly integrate the silos of data and develop just-in-time applications on this operational data hub. MarkLogic’s approach has been proven to be much more flexible and provides a much faster time-to-market than a relational database approach to similar problems.
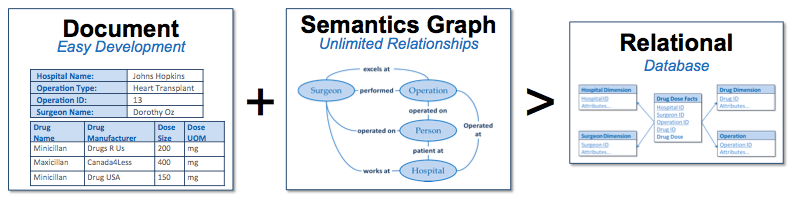
Document plus Triple Store provides more flexibility than just Relational.
Advantages of Multi-model Semantics + Document Approach
- “As-is” data allows for strong data governance (lineage, history, life cycle, security)
- Ontology can be used to tag or enrich documents with triples
- Unified query view can use ontology to find similar content across different sources
- Flexible API can support SPARQL, Search via REST, and/or Java or JavaScript
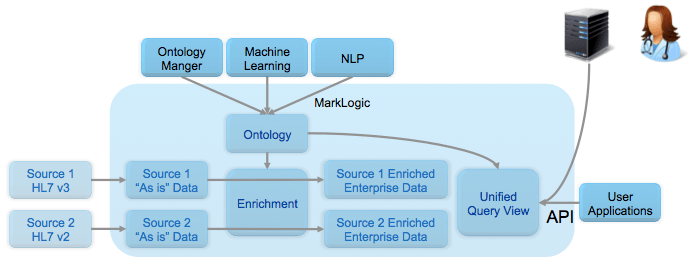
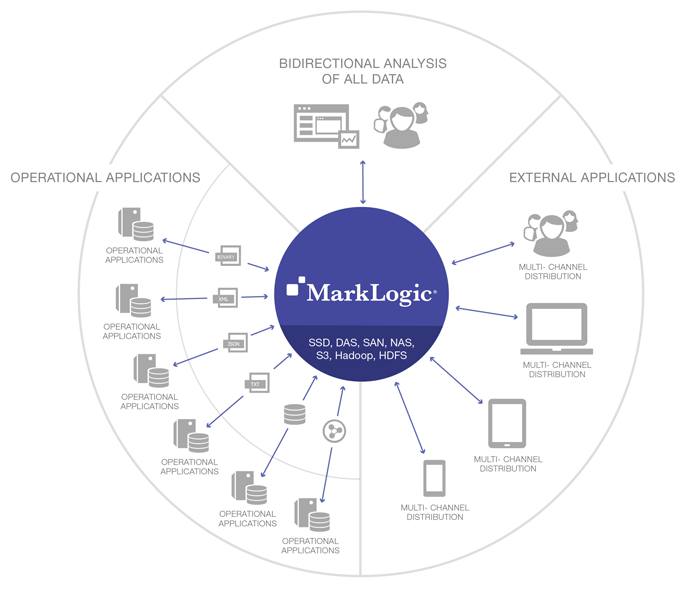
The figure above depicts how the multi-model semantic and document architecture can be implemented with the MarkLogic platform to create an ODH. Each source that needs to be accessed by APIs or end-user specific applications may have its own standard way of formatting, storing and providing the business objects (e.g. Patient, provider, procedure, etc.) that need to be aggregated. MarkLogic’s flexible data model allows you to bring in these objects and store them in the form of “As-Is” documents. An Ontology manager and/or other techniques such as machine learning or natural language processing can be used to create and manage the ontologies that map similar semantic fields together and that provide the relationships between the business objects. Because MarkLogic has a built-in Enterprise Triple Store, these ontologies can be stored directly in MarkLogic. The incoming data can be enriched with the semantic mappings defined by the ontologies on write. The unified query view can also take advantage of the ontology to provide further semantic query capability on read through query expansion using both SPARQL and search. The combined content from all the registries is then exposed through a REST API for other systems or applications to access.
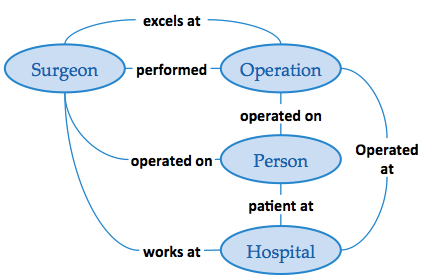
The image below shows how semantics can be used to query for and harmonize/normalize similar semantic concepts such as a patient ID from registries that store data in different formats. In Healthcare, HL7 v3, HL7 v2, and FHIR all have the concept of a patient ID, however, each of them have a unique syntax for identifying this concept. Semantic triples can be used to say each of these syntaxes are really referring to the organization’s enterprise patient id concept.

Intrigued by our proposal, the team has decided to go with the multi-model document and semantics architecture. I will post updates as they make progress.

Imran Chaudhri
At Progress MarkLogic, Imran focuses on enterprise quality genAI and NoSQL solutions for managing large diverse data integrations and analytics to the healthcare and life sciences enterprise. Imran co-founded Apixio with the vision of solving the clinical data overload problem and has been developing a HIPAA compliant clinical AI big data analytics platform. The AI platform used machine learning to identify what is truly wrong with the patient and whether best practices for treatment were being deployed. Apixio’s platform makes extensive use of cloud computing based NOSQL technologies such as Hadoop, Cassandra, and Solr. Previously, Imran co-founded Anka Systems and focused on the execution of EyeRoute's business development, product definition, engineering, and operations. EyeRoute was the world's first distributed big data ophthalmology image management system. Imran was also the IHE EyeCare Technical Committee Co-chair fostering interoperability standards. Before Anka Systems, Imran was a founder and CTO of FastTide, the worlds first operational performance based meta-content delivery network (CDN). Imran has an undergraduate degree in electrical engineering from McGill University, a Masters degree in the same field from Cornell University and over 30 years of experience in the industry.
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Secure File Transfer
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites