MarkLogic from a Relational Perspective: Part 2

Data Modeling – From Relational to MarkLogic
This is the second in a series of blogs for people coming from a relational background, to help you understand the differences in how MarkLogic handles data integration and access.
TL/DR:
- Data modeling in MarkLogic is an iterative process that focuses on meeting specific project goals for user data access, versus the relational approach that requires significant upfront data modeling and ETL.
- With MarkLogic, best practice is to maintain data as it was originally received/ingested, while enhancing and harmonizing as additional items.
- Because MarkLogic is a smart database, in a 3-tiered architecture, it’s best to move some traditionally middle-tier functionality into the data tier.
- MarkLogic Template-Driven Extraction (TDE) allows for the creation of SQL views of document data, e.g., to support end-user applications like BI tools.
Data modeling is a critical element of IT. In fact, after the creation of the computer, the data dictionary is the most important innovation in computer science. With a data dictionary, it is possible for users and applications that have no knowledge about the internals of the application, which created the data, to understand and access its data.
However, in recent years, data modeling has become a primary cause of missed deadlines and failed projects. The reason for this is that the data modeling and transformations required for large IT projects often take a project beyond its deadlines before actual development starts.
Data modeling in MarkLogic minimizes this problem. Modeling in MarkLogic is different than modeling in a relational environment. This is true for a variety of reasons:
- Data can be modeled after it is loaded, as well as before.
- MarkLogic does not require every attribute to be modeled.
- In MarkLogic, it is possible for every document/record of data to have a different schema.
- MarkLogic’s Universal Index treats implied schemas embedded in data (attribute names) as data and, without any formal modeling, exposes substantial capabilities such as structured queries without the need for a formal data dictionary/schema.
All of this leads to a very different modeling experience that can reduce modeling and ETL to a fraction of that in traditional systems.
Thinking about Modeling
The key to effective data modeling in MarkLogic is to understand that, in complex systems, data modeling should be incremental and geared towards the needs of your deliverables.
In relational systems, modeling is a waterfall approach where schemas are defined and ETL processes are created to convert data to conform to this model before data is loaded. In simple cases, this works fine.
However, when it is necessary to consolidate multiple overlapping source systems, the waterfall approach breaks down. Modeling and ETL efforts sometimes take so long that project deadlines may have passed before development can even start. This causes many large IT projects to fail.
With MarkLogic, you should understand your long-term goals but focus modeling on what you need to complete the deliverables for your next project. The work you do for your first project is built into your database and becomes the base for your next project. The work done for one project does not become a separate silo.
In general, to get started, you should look at the kind of data access your users need. The data elements that need to be explicitly modeled include the columns in the where clause—anything that needs to be aggregated—and broadly, anything that needs to be harmonized (different field names for the same thing, different units, etc.).
Harmonization of fields that are not critical to your next deliverable can be delayed until they become a priority. Because of the power of the Universal Index and search, and because MarkLogic keeps data that is not modeled, you still retain access to all your data, even if you do not explicitly model or harmonize it. It remains possible to perform structured searches on data elements that have not been formally modeled, and it is also possible to do Google-style searches on unmodeled data. You can always display all of the data in your documents, even if they have not been formally modeled or harmonized.
The cost of not modeling every data element is far less in MarkLogic than is the case in a relational database.
Understanding Your Data
As mentioned above, one of the key benefits of a data dictionary is that it makes data understandable. With MarkLogic, data is stored in a way that makes it much easier to understand even without any formal modeling. While modeling is generally still necessary, understandability is less dependent on having a data dictionary.
Because relational forces modeling to be done in the form of rectangles of columns and rows, complex objects are broken out and stored as separate items. This makes it difficult for users to easily examine and understand the data. In fact, this is so difficult that, with complex systems, data access is often restricted to skilled DBAs who are trained on accessing it.
Data organized as documents or objects is inherently easier to understand than relational data. With MarkLogic, the data is stored in the way it was created by the domain experts who generated it. Because of this, it is less essential to fully model every aspect of the data.
This does not mean that formal modeling is not critical. At a minimum, it is often necessary to examine a conceptual view of the data instead of looking at examples of individual documents and records. And, accessing data through ODBC/JDBC obviously requires a formal schema.
MarkLogic and Three-tier Architectures – MarkLogic as a Smart Database
Three-tiered architectures are a common approach for application development. The idea is that business logic is maintained in the middle tier, data is stored in the data tier and the user interface has its own tier. Keeping business logic out of the data tier and especially the UI tier is considered desirable as it avoids the need for duplicate implementations of business logic when new UIs (cell phones, etc.) or data stores are used.
MarkLogic is compatible with this approach, but the optimal use of MarkLogic requires moving some traditionally middle-tier functionality into the data tier.
One reason for this is that in MarkLogic, it is possible to include transformation code as part of the data model. Having this functionality in the data tier clearly offers the possibility for dramatically improved data infrastructures. By including the original data along with the canonical data as well as the transformation in one place, provenance and lineage issues are significantly diminished.
The second reason is that MarkLogic is a smart database. The integration of semantic and document data allows MarkLogic to understand its data far more than is possible in a relational-based system. Semantic triples allow concepts to be linked to specific data elements, make it possible to create hierarchical relationships and also to link documents. Loading these triples into MarkLogic makes it possible for MarkLogic to access your domain knowledge about your industry and your organization to enable more accurate and precise data access.
Data modeling in MarkLogic should generally include ontologies that describe your organization and the area the application is geared towards. It should also describe the relationships between entity types.
Modeling Mechanics
In relational systems, there is a schema that defines the structure of each table in the database (including what kind of data can be placed in each data column), the links between tables (implemented through foreign keys) and the indexes associated with each table. This schema is passive and describes the data. All data must fit into this schema.
On top of the table, structured views can be created. Views link data between different tables into a single whole and can hide columns that are not needed by the users of the view.
With MarkLogic, the relational approach can be done, using our Entity Services feature. MarkLogic schemas, however, can be much broader than just tables.
In MarkLogic, data modeling is generally incremental. With this approach, data is first loaded with no explicit, or only a limited, schema. As further harmonization needs are identified, the schema and transformations are enhanced (changes are applied to existing data, not just incoming data). The entire data set remains accessible and can be searched and queried—even those aspects that have not been formally modeled. SQL views can be created for data even when there is no formal schema defined.
Formal Modeling – Entity Services
In MarkLogic, a formal data dictionary is created with a feature called Entity Services.
An important difference between MarkLogic and relational systems is that when using this kind of prescriptive schema, some of the data transformations are an explicit part of the data dictionary and not separate steps handled outside of modeling. Also, the data model can regularly be extended to include more data attributes without needing to do an export/reload or otherwise making the data inaccessible. This is possible because the best practice for MarkLogic is to always maintain data as it originally was received while enhancing and harmonizing as additional items. In relational systems, this is difficult to do.
Modeling – Key Points
With Entity Services, data models are defined in JSON or XML as a combination of documents and triples. Model basics can be defined in Entity Services through a graphical tool and extended with ontologies.
Once the model is built, MarkLogic creates processes to transform heterogeneous data into a canonical model. As these processes are defined along with the descriptions of the entities, MarkLogic can combine the data formats and transformations as parts of the model.
MarkLogic performs code generation to enable the automatic creation of links between entities, the tracking of lineage, the generation of SQL views of the model, and templates for the loading of heterogeneous data into the common model and other tasks.
Creating Views with SQL
MarkLogic Template Driven Extraction (TDE) allows for the creation of SQL views of document data.
It is easy to go from:
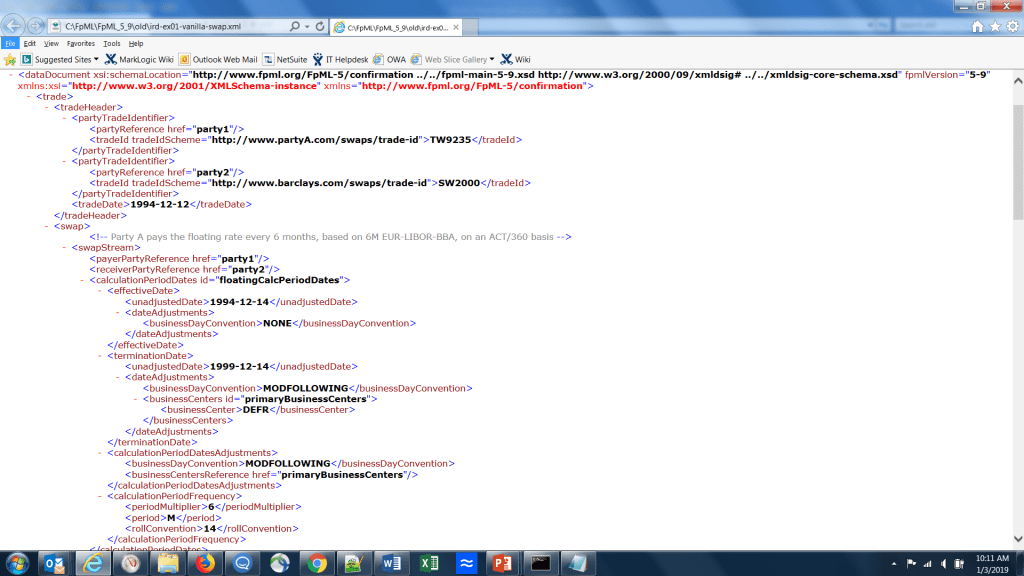
to:
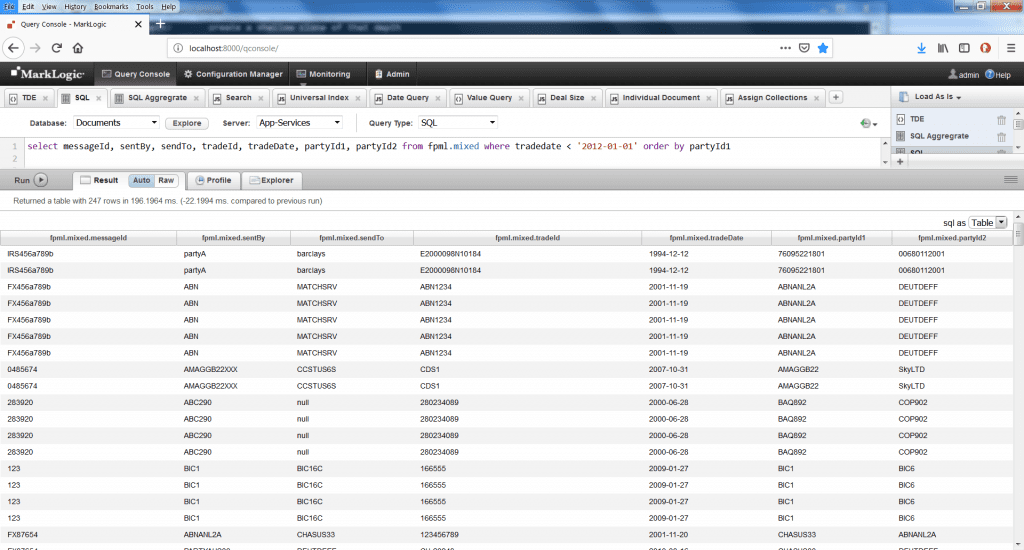
MarkLogic is able to take complex, document-oriented data and allow users to access via SQL through the use of templates to describe how the data is laid out in the documents.
The views can pull data from complex, object-oriented, underlying data sets to populate flat SQL views.
Defining an SQL view does not limit access to the data in any way. The same underlying data can also be accessed as XML, JSON, through REST calls, from the MarkLogic Java Client API and other methods.
Limiting MarkLogic to SQL as the primary form of data access in a MarkLogic database is not the optimal way to build a MarkLogic-based application. This is because the application will be cheating itself. Relational technology is much less expressive and powerful than MarkLogic.
Having said that, MarkLogic does have SQL extensions that allow access to functionality like the Universal Index, even against data attributes that are not a part of the SQL view.
For some applications, like BI tools, SQL views are often the primary way end-users access formal data models in MarkLogic.
Learn More
- Read the other posts in this series:
- [White paper] Rethink Data Modeling
- [Blog] Old Dog, New Tricks – and Agile Modeling

David Kaaret
David Kaaret has worked with major investment banks, mutual funds, and online brokerages for over 15 years in technical and sales roles.
He has helped clients design and build high performance and cutting edge database systems and provided guidance on issues including performance, optimal schema design, security, failover, messaging, and master data management.
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Secure File Transfer
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites