
I am a fan of big, sweeping technology trends, and you may be as well. They really help to put things into a reasonable context, and – at least personally – help me decide what’s important, and what’s not.
 Let’s start with an uber-trend: using computers to automate and improve human activities. From the mid-1960s onwards, there’s been a bottomless appetite for “math meets data.”
Let’s start with an uber-trend: using computers to automate and improve human activities. From the mid-1960s onwards, there’s been a bottomless appetite for “math meets data.”
Along the way, we had databases, ERP, integrated cloud suites, data warehouses, IoT, analytics, now data lakes and machine learning – essentially lots of data meeting lots of math to better automate and coordinate human activities.
As a society, I’d guess that we collectively spend many tens of trillions of dollars on this theme annually, and seem to want even more, preferably using a cloud. Obviously, more data needs to meet more math.
But there appear to be emerging limits to this investment theme – initially cropping up in a few places, and now much more widespread. Big spenders are seeing declining marginal rates of return on their investment. It’s not dissimilar to playing out an oilfield: maybe the answer isn’t to drill a bunch more wells.
I’d describe it as what happens when you hit the knowledge wall.
The Limits of Data Meets Math
I’ve done my tour of duty in the analytics world, it’s easy to become enamored with the power of math and data. For example, just about anything can be a sensor, and as a result there’s infinitely more data available, making the math even more powerful and fascinating.
That being said, it’s also easy to lose sight of what all the data and math might really mean in the real world. We capture data at its source, then process and reprocess it – usually stripping it of its rich context along the way.
The binary representation persists, but its meaning often diminishes. We’ve lost what we know about the data and what it might mean to us.
At some point, a data set becomes a mystery artifact: from whence did this come, and what might it mean? Indeed, there’s a whole subspecialty of ingesting “dark data” about which little is known, and trying to infer meanings via AI clustering techniques. It can be an expensive way to learn about your data.
 Call it a problem of shared context: there’s human knowledge required to interpret any meaning.
Call it a problem of shared context: there’s human knowledge required to interpret any meaning.
Unless that human knowledge can be continuously captured, nurtured, and applied, the investment in data and math will progressively lose real-world context, and essentially hit an investment wall.
As investment scale increases in various dimensions (data variety, people, sophistication, etc.) the “shared knowledge problem” also seems to scale as well. There’s only so far you can get with “researcher notebooks” – it isn’t codified, reusable and verifiable knowledge.
I believe it sneaks up on people. If you find your team arguing a lot about what the data might mean, you’ll see the signs – people are using substantially dissimilar contexts to evaluate the same evidence vs. a shared, agreed one.
Feel free to spend more money on smart people, better tools, additional data sources, and so on. They’re all good. But I would argue your marginal rate of return on those investments will diminish, unless analytics insights are coupled to real-world, on-the-ground knowledge – the semantic knowledge graph – and the data that created it.
 Why am I bringing this up? Because I see very serious investment patterns around “math meets data” with no corresponding investment in creating the context – the shared organizational knowledge – that’s essentially the other part of the equation.
Why am I bringing this up? Because I see very serious investment patterns around “math meets data” with no corresponding investment in creating the context – the shared organizational knowledge – that’s essentially the other part of the equation.
I can see where a lot of people are going to be unhappy before long.
To be clear, this particular problem doesn’t show up until things get big. In smaller environments, informal knowledge-sharing networks appear to be sufficient. But in larger environments, that mechanism doesn’t appear to be effective, creating a serious problem.
You’ll perhaps see this manifested as a perceived lack of trust in analytical work products.
That’s to be expected – unless the analytic insight can be walked back to the data ingested onward – trust will be difficult to earn, and important results may not otherwise be put to use.
The Value of the Semantic Knowledge Graph
In simple terms, the semantic knowledge graph codifies everything that is known about a topic – and what it means. It is not entirely dissimilar to the way DNA “knows” how to build a new organism. Ideally, it is an active, learning entity that not only reflects everything that is known but is intended to be used everywhere – including grounding analytics efforts.
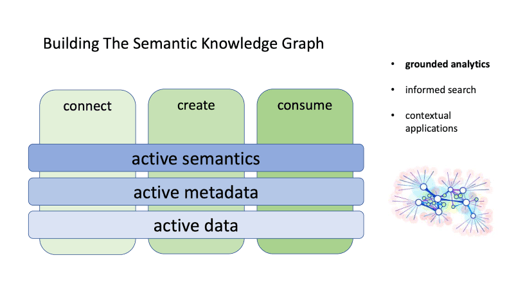 To construct a semantic knowledge graph, you need three things: data to interpret, tools to help capture and interpret meaning, and active metadata to connect the two.
To construct a semantic knowledge graph, you need three things: data to interpret, tools to help capture and interpret meaning, and active metadata to connect the two.
All three should be “active” and “connected” in the fullest sense. Lose the connections between the layers, lose the connection with grounded reality.
If it helps, think of packages and their labels being kept together. You’re ingesting data, and keeping it together with everything you know about it – and why. The metadata layer provides encoding, the semantic layer provides meaning.
You’ll find that this graph is quite important at three times: when trying to interpret the meaning of new data, when enriching the graph itself, and – ultimately – when it’s used for informed search, contextual applications – and grounded analytics.
Its value transcends analytics alone, it can ground the entire organization in a shared reality that can change and evolve rapidly.
Back to Large Analytics Environments
Ideally, analytics efforts should be working off the same knowledge graph as everyone else, but that’s not always the case. There are many examples of larger analytics functions recognizing the nature of the problem, and trying to do something similar within their own confines.
Unfortunately, these analytic-centric efforts appear to fall into two traps. First, by nature of their origin, it’s difficult for them to tether to shared, on-the-ground organizational reality. To be fair, it’s an enormous investment of time and effort, and things would be better if they could simply consume an existing knowledge graph vs. create a new one.
The second trap is a bit more insidious – the analytics teams have created various repositories of shared knowledge, but (a) it’s often disconnected from the source data, and (b) it’s not constructed in a shared, reusable and verifiable manner. What knowledge does exist doesn’t exist in codified and extensible form.
There’s a Pattern Here
Stepping back a bit, this situation is not unique to large analytical efforts. Indeed, there are plenty of examples of teams of very smart people attempting to reason over large quantities of inherently complex data. Intelligence, finance, biochemistry, physics – the list goes on and on.
At some point, each has come to the realization that formalizing what we know – and how we know it – becomes more important than the data itself. By doing so, we scale human capacity to think and reason more effectively.
Because there’s only so far you can get with math and data.

Chuck Hollis
Chuck joined the MarkLogic team in 2021, coming from Oracle as SVP Portfolio Management. Prior to Oracle, he was at VMware working on virtual storage. Chuck came to VMware after almost 20 years at EMC, working in a variety of field, product, and alliance leadership roles.
Chuck lives in Vero Beach, Florida with his wife and three dogs. He enjoys discussing the big ideas that are shaping the IT industry.
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Secure File Transfer
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites