
Simplicity.
Why can it be so hard to achieve? Something I’ve learned with problem solving is: if you find yourself spiraling into a pit of complexity, often the right approach is to go back to the start and look for another way.
For centuries, astronomers struggled to map the paths of the stars and the planets. The more they tried to map their models to the actual data, the more complex these models became, involving wild calculations that would make even the most hardened mathematician cry. That was, until Copernicus came along and suggested: What if the earth wasn’t the center of the Universe, and everything revolves around it? What if, instead, the Earth revolved around the Sun? And just like, that these absurd and complex models were reduced to a beautiful simplicity.
Of course, astronomy is still a difficult subject; but by finding the right start, vast amounts of unnecessary complexity were removed from the problem.
Data Sources As Astral Bodies
MDM projects, are essentially the same thing. Instead of astral bodies you have data sources. Instead of geocentricism (the earth at the center of the universe model), you have relational technology; whole IT budgets have been wasted trying to make it fit this problem. The question then is, what is the corresponding heliocentric (earth revolving around the Sun) model?
First a definition: MDM comprises the processes, governance, policies, standards and tools that consistently define and manage the critical data of an organization to provide a single point of reference.
For critical (master) data two criteria are required:
- A single version of the truth: If you have a customer Christy Haragan registered as living in Winchester in one system, and Christy Haragan registered as living in London in another, it is advantageous to know which is the correct address.
- Clean data: If you have a street address residing in a city field, this is unclean data.
As you can imagine those two criteria are aspirational because organizations frequently will have a myriad of overlapping data, which arises from both organic growth, and immature data management.
To overcome this, organizations invest in huge squads of people who seek to consolidate, clean and de-duplicate their master data — and then manage this single true version of the truth going forward. They may wish to do this using a registry style (leave the data where it is, and instead maintain a registry of which data sits where), or a hub style (where they move the data into a single repository and manage it from there). In either case, because this is dealing with the most critical data to the business, a fully enterprise grade solution is required, with ACID transactions, HA, and DR to ensure data is always consistent, never lost, and always available.
There are, however, a number of challenges associated to the pursuit of this managed single version of the truth, which often results in very large multi-year multi-million dollar projects (in the best case), or outright failure (in the worst). Over two-thirds of all MDM projects fail!
Registry vs Hub
Registry approaches have the best chance of succeeding, but have the challenge that if the Christy Haragan entity is referenced (and perhaps duplicated) across multiple systems, the processes involved in maintaining a single version can become expensive and error prone (conflict resolution, for example). This approach works for smaller projects with smaller more localized data sets (e.g., spanning a single data center or perhaps geographic location), but as you can imagine doesn’t scale.
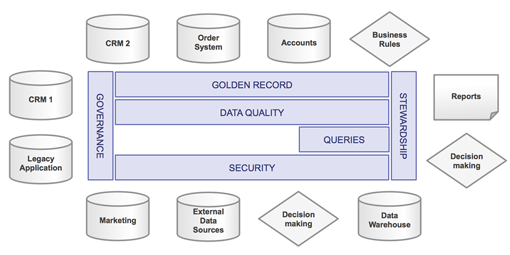
MDM Registry style: Data is left in the source systems and managed centrally.
The hub approach, does scale, but requires a domain model (e.g. Customer, Product, Account, etc.). Due to the inherent intricacy in any of these domains, these models are extremely large and complex. The process of mapping the source data onto these domain models is extremely challenging, expensive, and error prone. Moreover, as data is changed and re-arranged, (shape-shifting at its finest) the risk of breaking existing processes increases, and adds further risk and expense to the project.
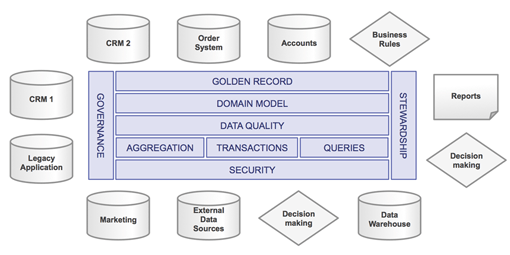
MDM Hub style: Data is mapped to a domain model and moved to the central hub to be managed.
On top of those constraints, a common challenge to both of these approaches is the inherent problem of data cleansing and data de-duplication. A successful data cleansing exercise might automate 80 percent of records, but that can still leave you with quite a bit! A modest number of a million records to process (a low number in MDM terms), this still would require 200,000 records to be manually cleansed. And in the case of multiple addresses, how would the system know which is correct? Maybe both are, maybe neither.
Heliocentric Solution for MDM
There are, however, two approaches that can be taken to address these fundamental and challenging problems with a traditional MDM solution:
- A schema-agnostic solution will ensure that the effort of consolidating data is reduced by orders of magnitude. Instead of having to develop – or buy – expensive, complex, and often insufficient domain models (that require expensive and brittle ETL processes to map to) a schema-agnostic approach will allow the data to be brought together painlessly, ingesting as-is.
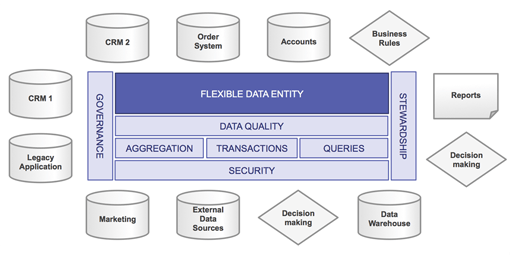
Operational Data Hub: Data is loaded as-is to the central hub to be managed.
And instead of a big-bang approach required by traditional MDM — which demands all data be mapped before the system is useful, a schema-agnostic approach is more flexible and responsive. Iterative transformation of data after ingest would allow businesses to focus on high value tasks first, testing each change for correctness, and being able to respond to business changes quickly. For data in invalid fields, a schema-agnostic approach means leaving the data in its original form (reducing the risk of breaking existing processes). The entry can be enriched with meta-data to indicate whether it’s a street address, zip code, etc.
- Instead of trying to reduce the truth to a single version, semantics can be used to link data. Instead of having to decide which address is correct, a link can be made to the two entries, and only when a business process is executed (or about to be executed) and requires a valid address to be known, would the business need to engage the potentially expensive task to ascertain the correct address.
Of course most schema-agnostic approaches won’t provide a lot of the enterprise grade features of ACID, HA and DR.
MarkLogic provides a schema-agnostic database platform allowing data to be stored in its original form, and enriched as necessary. Its semantics capability allows flexible links to be created between entities. But it has those highly-sought after enterprise features — so the business doesn’t sacrifice anything in adopting this new approach to managing it’s most critical data.
MDM, like Astronomy, is still a difficult topic. But by starting with the right approach, we can reduce large amounts of unnecessary complexity.
MarkLogic is MDM’s heliocentric solution.

Christy Haragan
What an exciting time to be alive! Technology is revolutionising our lives - our society - at an exponential rate: Global barriers are being eradicated; insight into our customers is becoming real-time; and more and more of our lives are becoming automated.
Business has been transformed by IT, and yet I believe we haven't even started to scratch the surface on what we can do with the technology available to us. Even our mobile phones provide the wealth of human knowledge in a heartbeat, with analytical capabilities that would require room consuming boxes only a few decades ago!
For me, technology is a passion and a hobby. To find myself with a career in this area in such amazing times is truly a blessing!
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Secure File Transfer
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites