
You may already be using Spark, and now you want to build an Operational Data Hub. But, it’s impossible without a transactional database — and that’s where MarkLogic comes in.
Apache Spark is the most popular open source cluster computing framework today. It offers a fast, in-memory data processing architecture that is easy to adopt and extremely powerful when you want to analyze huge amounts of data.
The core architecture of Spark abstracts the data processing concepts and mechanisms very nicely so that a Spark developer can apply a number of sophisticated analytical technologies like SQL, machine learning, or streaming analytics on a wide variety of datasets that may have been stored in a relational database like Oracle, a distributed file systems like Hadoop HDFS, or Enterprise NoSQL database like MarkLogic.
The question often gets asked, “Can Spark address our requirements for an Operational Data Hub? What else do we need?” The simple answer is NO. When it comes to build an Operational Data Hub, Spark alone or Spark along with Hadoop is not good enough. You need a database that can support transactions, security, allow flexible schemas, and provide a unified view across heterogeneous data. Additionally, you need the capabilities to implement data provenance, data privacy, and data retention policies in order to achieve industry specific regulatory compliance.
But that isn’t to say your investment in Spark is lost! Spark works as a Big Data processing framework and what you need is a NoSQL data integration platform that complements Spark to gain insights into day-to-day business operations.
Different Approaches to Spark
Now, as we start the discussion, let’s look at a couple of starting points that I have encountered. They reflect different viewpoints around open source and commercial technologies that offer distributed cluster computing architecture.
If you have experience using open source technologies like Hadoop, Hive, and other technologies, you may ask, “Doesn’t Spark simply replace the MapReduce framework within Hadoop? Why would I use Spark with any other database like MarkLogic when I already have Hadoop?”
On the other hand, if you have been using MarkLogic, you may say, “I’m already using MarkLogic to store and process my data in rich formats like JSON or XML. I can get answers to all my questions practically in real time. Why do I ever need another cluster computing framework like Apache Spark when I have MarkLogic?”
At the surface level, both questions are valid. In the today’s age of Big Data, a database like MarkLogic is not simply a data persistence layer but it also serves as a scalable data processing platform for enterprise applications. It enables developers to process the data close to where it is stored, in real time or near real time, and eliminates the need for a separate data processing framework. This means there is less delay in retrieving answers to your questions.
While the boundaries between a database and data processing framework are fading away when it comes to a modern database like MarkLogic, it’s equally important to look at a wide spectrum of requirements for data processing frameworks and identify which architecture is best suited to address those requirements.

On one end of the spectrum, you have highly operational applications where thousands and thousands of users are accessing the data concurrently. These users are making highly selective queries that are specific to their job.
For example in the Financial Services market, MarkLogic is commonly implemented as an Operational Trade Store. With a trade store, someone may need to look for all the information related to a specific swap transaction along with all the pre-trade correspondence to ensure that the transaction complies with all the applicable regulations in the region where that transaction took place. An analyst at a financial services company or a regulator may want to query for a specific instrument, its performance and associated news, analysis, reviews, etc.
As you can see, these queries are made against the combination of structured and unstructured information. The nature of queries may vary widely but generally, these are highly selective queries where end users know what exactly they are looking for and typically the response is expected in milliseconds.
The performance of a financial instrument may change at any second and users are looking for up-to-the-minute or up-to-the-second information. This is where MarkLogic shines because of its built-in search capabilities that enable extremely fast querying over constantly changing data. If you look at the data access patterns for the operational applications, the users are performing read/write operations. So, the database must have ACID compliance to ensure there is no data loss during concurrent insert or update operations. The database also needs to have built-in security to prevent any data breach.
On the other end of the spectrum, you have highly analytical applications that also need to operate on large amounts of structured and unstructured information. Within an enterprise, there is a relatively small set of users who are tasked to perform high-value business analytics. Typically this would be less than a thousand users, and includes business analysts, data scientists, and data engineers.
A good example of an analytical use case is log processing or analyzing machine-generated data. The volume of data is huge but users are not making queries for a specific log event. They want to analyze the log data in order to gain insight into user behavior pattern or a system behavior pattern. In order to understand these behavior patterns, all of the available log events need to be processed, then advanced analytical algorithms or machine learning algorithms need to be applied that help identify distinct patterns in user behavior or a system behavior. The insights gained through this analysis can help to grow user adoption, reduce customer churn, improve operational efficiency, and much more.
From data access standpoint, analytical applications tend to be read only applications. They need a data processing platform that can perform massive parallel computations over large, immutable datasets. Apache Spark addresses these requirements very well.
So now, we’ve made clear distinction between the requirements around operational and analytical applications and identified MarkLogic and Apache Spark as our “go to” architectures for these applications. Our next question is, “Which technology should I use for which use case?” There are indeed some overlaps, and it’s not always that clear.
When it comes to building a real-world application, you may frequently come across scenarios where requirements are all over the spectrum. You may need to address operational and analytical requirements together in the same application in order to meet your business needs and as a result, you need your operational and analytical data processing platforms to work well together.
In the next part of this blog post, I will discuss a potential solution architecture that can leverage the power of MarkLogic and Apache Spark together to handle a wide variety of different use cases.
MarkLogic Operational Data Hub
We see the Operational Data Hub as a new emerging enterprise data integration pattern where customers are achieving huge success. The main goal of an Operational Data Hub is to integrate enterprise data silos and provide a single reliable and secure data platform to manage the integrated operational data. Operational Data Hubs converge operational and analytical worlds by providing actionable insight into operational data, enabling enterprise organizations to become data driven, not only in terms of strategic decision making but in day to day operations.
From the perspective of a Chief Data Officer (CDO), or CIO, an Operational Data Hub is a key asset in implementing governance practices across the organization. Architecturally speaking, the Data Hub is non-disruptive. While it enables the organization to make their business operations run smoother and more efficient, they do not have to throw away any architectural components within their existing data landscape. And, over time when data has gone through all downstream operational processes, it can be easily moved from the Operational Data Hub into a data warehouse where it can be consumed by business intelligence applications.
Operational Data Hub With MarkLogic and Spark
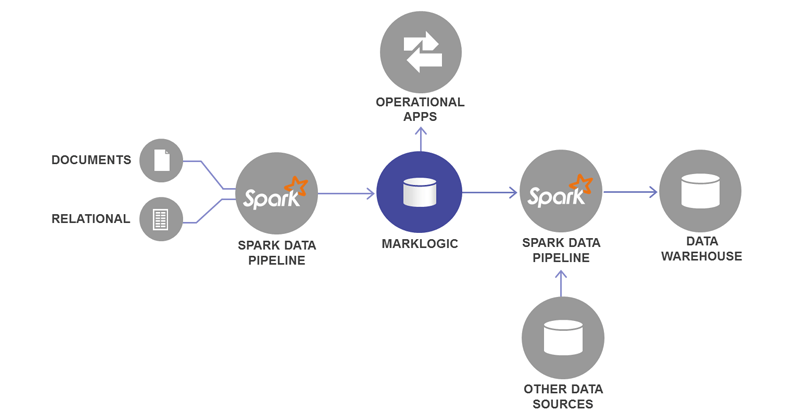
MarkLogic works very well as an Operational Data Hub. When Spark works alongside MarkLogic, the Operational Data Hub is even more powerful.
To better understand the Operational Data Hub using MarkLogic and Spark, let’s break it down by discussing the variety of use cases and the best way to handle them using MarkLogic and Spark.
- Load data from external sources into MarkLogic and transform that data on the fly with Apache SparkThis is really the data movement and data transformation scenario. Since MarkLogic is a document database that can support rich queries over rich data structures, you would typically capture your business entities in a document within MarkLogic.For example, your documents within MarkLogic could represent a customer, a patient, a sales order, an insurance claim and so on. Since most enterprise applications store this kind of information in a relational database, you will typically run into a scenario where your customer information is spread across 20 to 30 different source tables or your transactional information like a sales order is spread across 50 to 100 source tables. Now, if you want to perform bulk data movement and data transformation on the fly, reading the data from multiple source tables and loading that information as a customer document or a sales order document within MarkLogic, you need a batch data processing framework to orchestrate this data movement job.Spark is a very good candidate for this scenario. You can perform appropriate joins and filters across the source tables using Spark capabilities. Spark can support batch data movement as well as streaming of changed data within the source systems. When it comes to transforming tabular data into a rich hierarchical data structure that can be represented as JSON or XML document in MarkLogic, you can either do this kind of transformation within the Spark layer or you can do it within MarkLogic using server-side JavaScript.
- Aggregate data that comes in different shapes and formats with MarkLogic.MarkLogic stores data as documents, and can handle data aggregation and data harmonization very well. First of all, it does not require an upfront effort to come up with a data model that can accommodate the data from a wide variety of source systems.MarkLogic enables loading data in a source specific format. So customer data that comes from a Salesforce system and an ERP system will look different but can be easily loaded and queried in MarkLogic.Once data is loaded in MarkLogic, you can harmonize the data by standardizing the data structures or parts of data structures so that you can provide a unified view of your enterprise data. With the Flexible Data Model and “Ask Anything” Universal Index within MarkLogic, you can achieve quick ROI on your data harmonization project. You can execute the project in a truly agile fashion rather than falling into the relational trap where upfront efforts required to model the data take so long that in many cases the projects may exhaust all the budget allocated to it and may even shut down before business users can execute their first query.
- Get highly concurrent transactions and secure query execution over changing data with MarkLogicOperational applications powered by data hub need rich query capabilities and ability to write back to the data hub. MarkLogic addresses this need with its focus on security and ACID compliance. MarkLogic architecture scales very well not only to accommodate the large volumes of data but also large volume of concurrent user requests.MarkLogic is being used for a number of mission-critical applications within highly regulated environments within Financial Services, Healthcare and Government agencies since it meets the security standards defined within these industries.
- Conduct operational BI and reporting in real time or near real time with MarkLogicHere we are talking about insights into day to day business operations where queries tend to be much more granular in nature and you want answers in real time or near real time so you know what’s going on within your business area at any given moment. In other words, you don’t want to wait for your overnight ETL job to run before the data is propagated into your BI dashboards or reports. MarkLogic has a built-in search engine that is capable of leveraging its universal index along with other rich indexes to address operational BI requirements.
- Data Warehousing and advanced multi-step analytics with Apache SparkEnterprise data moves through a particular lifecycle. For example, the orders that have been closed for more than a week or a month, whatever your business policy is, requires all the transactions that reach certain status to appear in your Enterprise Data Warehouse system. So, you are taking the aggregated operational data from the data hub along with potentially other data sources to populate your enterprise data warehouse.You can build this data pipeline using Apache Spark. In this case, the Spark data pipeline reads data from MarkLogic, transforms that data into appropriate schema (typically a star schema) and loads the data into your data warehouse.
- Loop insights derived from analytics into operational applications with Apache Spark and MarkLogicHere we are taking the analytics scenario further, where you don’t simply want to populate the BI dashboard as a part of the analytical process but loop the analysis output back into the operational processes.For example, you can take the historical transactional data to train a machine learning model and then use that machine learning model to classify the new transactions as a part of risk assessment or fraud detection scenario. In this case, you can use machine learning and stream analytics capabilities of Apache Spark along with MarkLogic to build intelligent operational applications.
Next Steps With Spark and MarkLogic
So there you have it! It’s time to wrap up this discussion for now. We looked at distinct technical challenges that can be addressed using MarkLogic and Apache Spark. MarkLogic is a great solution when it comes to building operational applications that require support for highly concurrent, secure transactions, and rich query execution over changing data while Apache Spark provides sophisticated analytics capabilities by performing massive parallel computations over large immutable datasets. Many real world use cases tend to be hybrid in nature (i.e. operational + analytical) and benefit greatly by using both MarkLogic and Spark together.
If you are an enterprise architect or are involved in planning out how to build and use an Operational Data Hub, we recommend that you learn more about Operational Data Hubs built using MarkLogic.
If you are a developer and are interested in taking a deeper dive, you can watch a recording of my presentation from MarkLogic World, Putting Spark to Work With MarkLogic where I discuss this topic in more detail as well as my developer blog, How to use MarkLogic in Apache Spark applications.
And, if you want to get straight to work, building something, visit the GitHub project MarkLogic Spark Examples as well as MarkLogic Data hub on GitHub.

Hemant Puranik
Hemant Puranik is a Technical Product Manager at MarkLogic, with a specific focus on data engineering tooling. He is responsible for creating and managing field ready materials that includes best practices documentation, code and scripts, modules for partner products, whitepapers and demonstrations of joint solutions - all this to accelerate MarkLogic projects when using ETL, data cleansing, structural transformation and other data engineering tools and technologies.
Prior to MarkLogic, Hemant worked more than a decade at SAP and BusinessObjects as a Product Manager and Engineering Manager on a variety of products within the Enterprise Information Management product portfolio which includes text analytics, data quality, data stewardship, data integration and master data management.
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Secure File Transfer
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites