Relational Databases Are Not Designed For Scale

Relational databases are designed to run on a single server in order to maintain the integrity of the table mappings and avoid the problems of distributed computing.
We’re at a tipping point with data volume. In my last post, I showed the stat from EMC about how the digital universe is expected to grow from 4.4 zettabytes in 2013 to 44 zettabytes in 2020 (remember a zettabyte is 1 trillion gigabytes). That’s hockey stick growth, and we’re just at the start of the curve. Organizations have millions of users and petabytes of data. They run their applications in the cloud to deliver dynamic content to millions of desktop, tablet, and mobile devices across various geographical locations.
Today, Business Is Digital
I see the big change being that paper files are no longer the system of record, databases are—we store everything. I previously did product management at large government organizations where they are all undergoing or have undergone massive “modernization” efforts (i.e. business transformation projects… here is an overview) that involve moving from antiquated paper processes in which documents are faxed in, scanned, and stored in a legacy mainframe or relational database to doing everything electronically on-demand. These organizations used to just store a few key items from a document electronically, but with these changes, they now need to store all of the data from each form, letter, regulation, profile, email, phone call, chat, investigation, decision, etc.
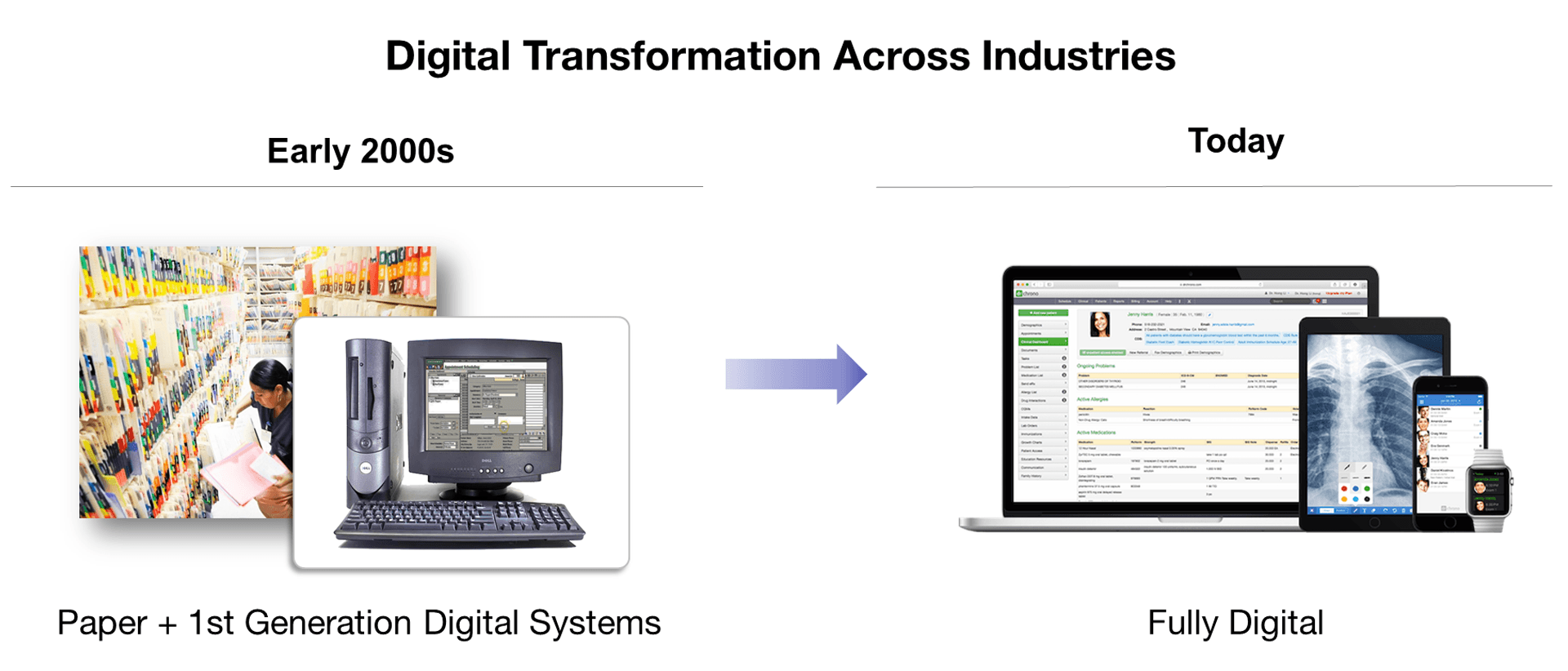
This sort of transformation has happened, or is happening, across every industry. Today, businesses run completely different than they did even just a decade ago. We went through a period of change in which paper records were still heavily relied on. But successful business are now running everything digitally. In the book, Leading Digital, the authors discuss a study they did in which organizations that are “digital masters”—having successfully use technology to transform their business—have 26 percent high profit margins than their peers.
To handle this new reality in which they must run everything about their business online, organizations need scalability (adding capacity for more data and more users) and elasticity (the ease in which the system scales, typically referring to the ability to scale back down when user demand dissipates).
Scaling Relational Databases Is Hard
Achieving scalability and elasticity is a huge challenge for relational databases. Relational databases were designed in a period when data could be kept small, neat, and orderly. That’s just not true anymore. Yes, all database vendors say they scale big. They have to in order to survive. But, when you take a closer look and see what’s actually working and what’s not, the fundamental problems with relational databases start to become more clear.
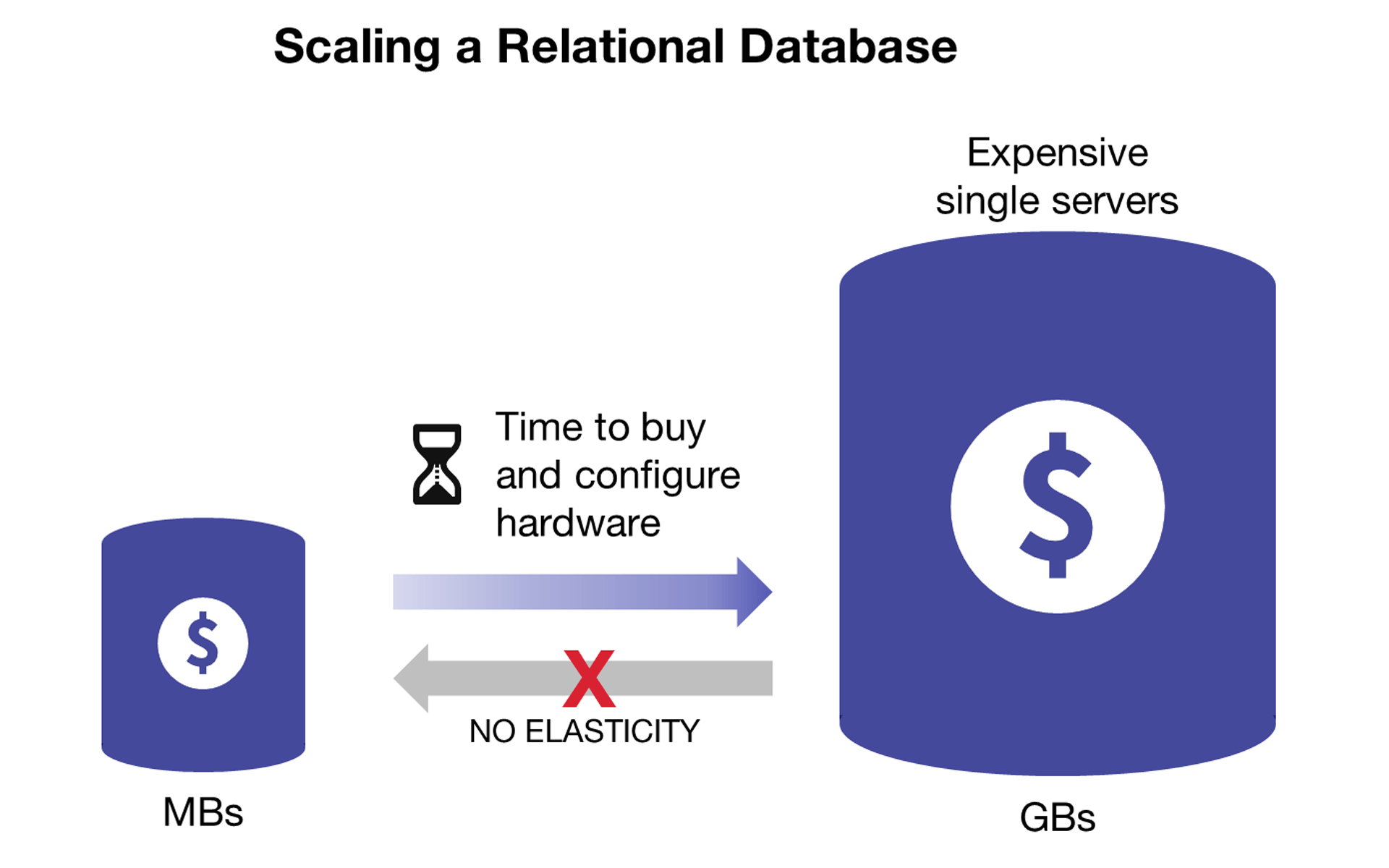
Relational databases are designed to scale up on expensive single machines
Relational databases are designed to run on a single server in order to maintain the integrity of the table mappings and avoid the problems of distributed computing. With this design, if a system needs to scale, customers must buy bigger, more complex, and more expensive proprietary hardware with more processing power, memory, and storage. Upgrades are also a challenge, as the organization must go through a lengthy acquisition process, and then often take the system offline to actually make the change. This is all happening while the number of users continues to increase, causing more and more strain and increased risk on the under-provisioned resources.
New Architectural Changes Only Hide the Underlying Problem
To handle these concerns, relational database vendors have come out with a whole assortment of improvements. Today, the evolution of relational databases allows them to use more complex architectures, relying on a “master-slave” model in which the “slaves” are additional servers that can handle parallel processing and replicated data, or data that is “sharded” (divided and distributed among multiple servers, or hosts) to ease the workload on the master server.
Other enhancements to relational databases such as using shared storage, in-memory processing, better use of replicas, distributed caching, and other new and ‘innovative’ architectures have certainly made relational databases more scalable. Under the covers, however, it is not hard to find a single system and a single point-of-failure (For example, Oracle RAC is a “clustered” relational database that uses a cluster-aware file system, but there is still a shared disk subsystem underneath). Often, the high costs of these systems is prohibitive as well, as setting up a single data warehouse can easily go over a million dollars.
The enhancements to relational databases also come with other big trade-offs as well. For example, when data is distributed across a relational database it is typically based on pre-defined queries in order to maintain performance. In other words, flexibility is sacrificed for performance.
Additionally, relational databases are not designed to scale back down—they are highly inelastic. Once data has been distributed and additional space allocated, it is almost impossible to “undistribute” that data.
NoSQL Databases are Designed for Scale
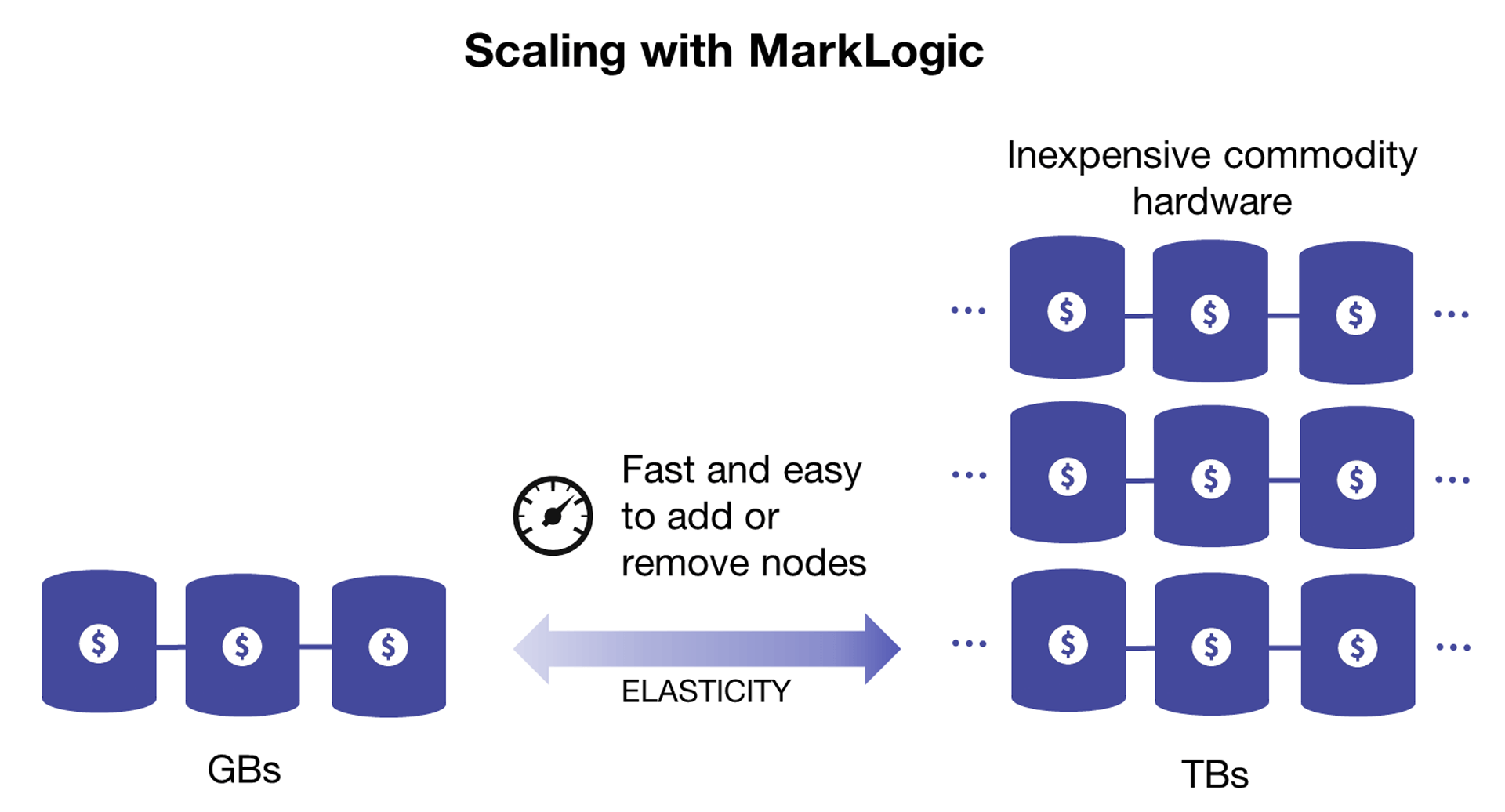
MarkLogic is designed for scalability and elasticity
Rather than be constrained by the limits of single-server architectures, NoSQL databases are designed for massive scale on distributed systems (usually hundreds of Terabytes rather than tens of Gigabytes). They can scale-out “horizontally,” meaning that they run on multiple servers that work together, each sharing part of the load.
Using this approach, a NoSQL database can operate across hundreds of servers, petabytes of data, and billions of documents—and still manage to process tens of thousands of transactions per second. And it can do all of this on inexpensive commodity (i.e. cheaper) hardware operating in any environment (i.e. cloud optimized!). Another benefit is that if one node fails, the others can pick up the workload, thus eliminating a single point of failure.
Massive scale is impressive, but what is perhaps even more important is elasticity. Not all NoSQL databases are elastic. MarkLogic has a unique architecture that make it possible to quickly and easily add or remove nodes in a cluster so that the database stays in line with performance needs. There is not any complex sharding of data or architectural workarounds—data is automatically rebalanced across a cluster when nodes are added or removed. This also makes administration much easier, making it possible for one DBA to manage for data and with fewer headaches.
Read the next blog in this series that discusses why relational databases are not designed for mixed workloads or download the white paper, Beyond Relational, which covers all of the reasons why relational databases aren’t working in more depth.
All posts in this series:

Matt Allen
Matt Allen is a VP of Product Marketing Manager responsible for marketing all the features and benefits of MarkLogic across all verticals. In this role, Matt interfaces with the product and engineering team and with sales and marketing to create content and events that educate and inspire adoption of the technology. Matt is based at MarkLogic headquarters in San Carlos, CA and in his free time he is an artist who specializes in large oil paintings.
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Secure File Transfer
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites