Avoiding the Franken-beast: Polyglot Persistence Done Right

Why should people store many kinds of data in one place? Why not put the many kinds in many places? A customer of mine has learned the answer the hard way by doing the latter, so I thought I’d write it up as a case study so you don’t have to suffer the pain that it had.
Honestly, I am writing this for my benefit too. Watching a team try to integrate three or four different persistence and data processing products (the polyglot part) into some kind of “Franken-beast” is like watching a train full of ageing software architects drive off a bridge in slow motion.

Building the Franken-beast is difficult to do – and difficult to watch
Sometimes you do need separate, discrete systems – but with MarkLogic you can avoid most of that integration, so I’m going to write here about how to choose and why it matters.
Polyglot Persistence
Martin Fowler first wrote about “Polyglot Persistence” in a blog post in 2011, and the term has caught on. Today there are 85,000 Google hits on the phrase, and people who think and write about the database world acknowledge that we are all dealing with many different forms of data and that we need many different tools to make that work. Text data, binary data, structured data, semantic data. The term is “rising terminology” and we can all expect to hear a lot about it in the next few years.
The conventional understanding is that to achieve Polyglot Persistence you store each discrete data type in its own discrete technology. But polyglot means “able to speak many languages,” not “able to integrate many components.” This is where my customer got into trouble. The team took the traditional route of using multiple stores for multiple data types. This post covers the impact of storing two types – structured data and binary data – in two different stores instead of one integrated store.
MarkLogic enables polyglot persistence with a multi-model database instead, and at the end of this post I’ll cover how this team is now re-working the system into a simpler form using this capability.
The Example: Excel Worksheets
Back to this particular customer. To protect the innocent, I’m going to pretend this was a mortgage application system that takes in Excel worksheet submissions documenting assets and expenses as someone applies for a mortgage. The Excel worksheet comes in, something extracts the various incomes and expenses to XML, then both get stored to support the mortgage application process.
Once the Excel binary and extracted XML are stored, a workflow engine helps users review and approve (or reject) the submission. This basic flow can be found in many computer systems – from applying for a loan to submitting a proposal to do a big project or to apply to become a preferred vendor.
The part I’ll focus on here is that this class of system stores both the original, “un-structured”, binary data (.xslx, .pdf, .jpg) as well as the structured XML data extracted from the Excel.
Here’s the mindset that got my customer into trouble:
“MarkLogic is the best XML/JSON document store in the world – we get that! But binaries should go into a ‘content system.’ A CMS or DAM. Let’s use Alfresco to store the Excel and some generated PDF notices, and put the XML in MarkLogic – that way we use a best-of-breed system for each type of data!”
The resulting architecture looked something like this:
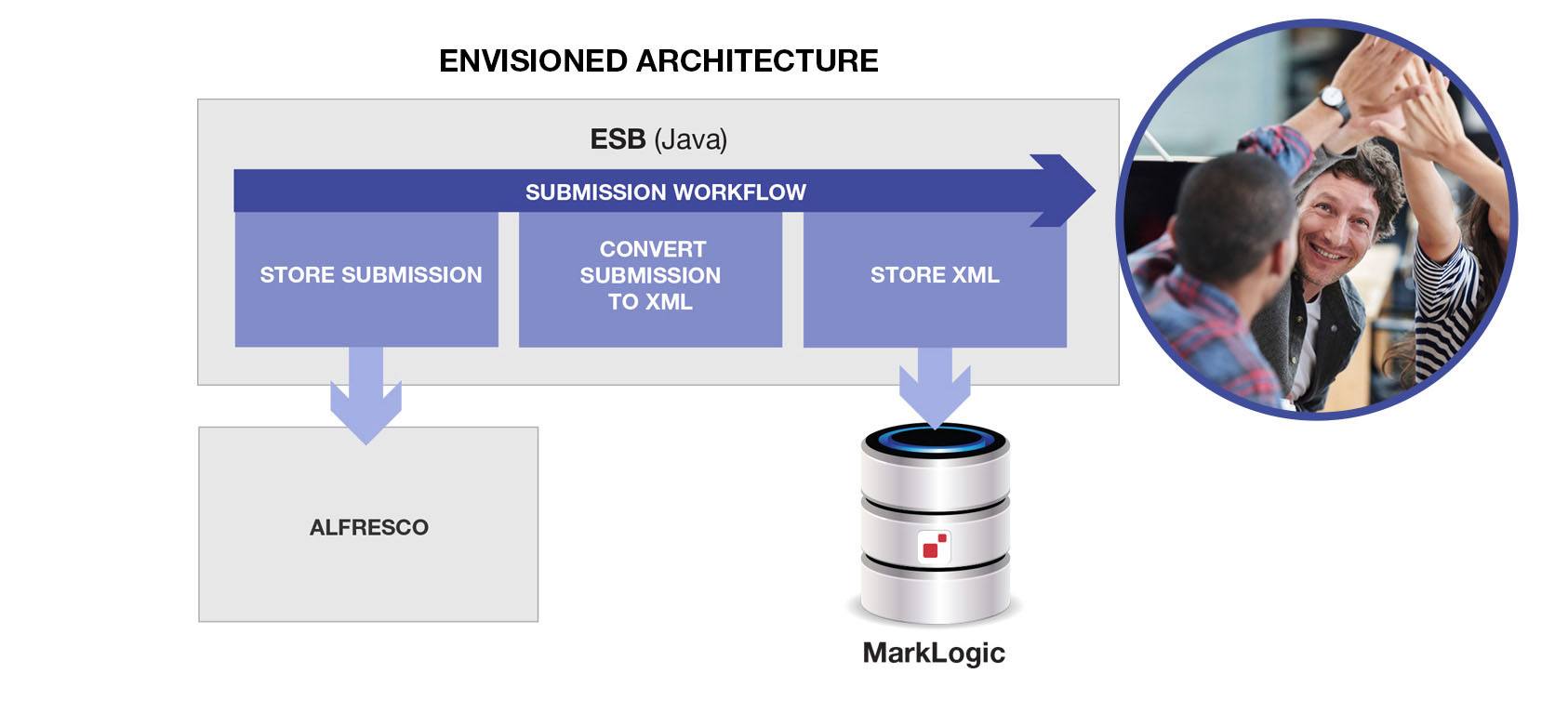
The resulting architecture looks something like the above. Simple, right? High fives all around to celebrate our collective genius.
Getting the Data Back Out
The first problem showed up as soon as we started to do something with the data. We needed to send it to an external, independent reviewer every week for quality control and to check on some complex business rules outside the scope of my customer’s implementation. These reviewers needed the XML records matching some criteria (let’s pretend it was super-jumbo loans, to fit with our example) and all the extracted data needed to be in zip files limited to 1GB each, uncompressed.
Easy, right? Get the new super-jumbo loans from last week, and stop when you hit 1 GB. Keep going until you have them all. We had a couple of problems:
- Only MarkLogic knows what is a super-jumbo for last week. Alfresco has limited metadata and the super-jumbo criteria (loan size, Jumbo thresholds per zip code) is in the Database, not Alfresco.
- It’s hard to know where to stop because you need to get the binary to know how big your zip file is.
This is a lot of data at busy times, so they used Spring Batch to coordinate long-running batch processing jobs. Suddenly we have a third component, adding a little more complexity.
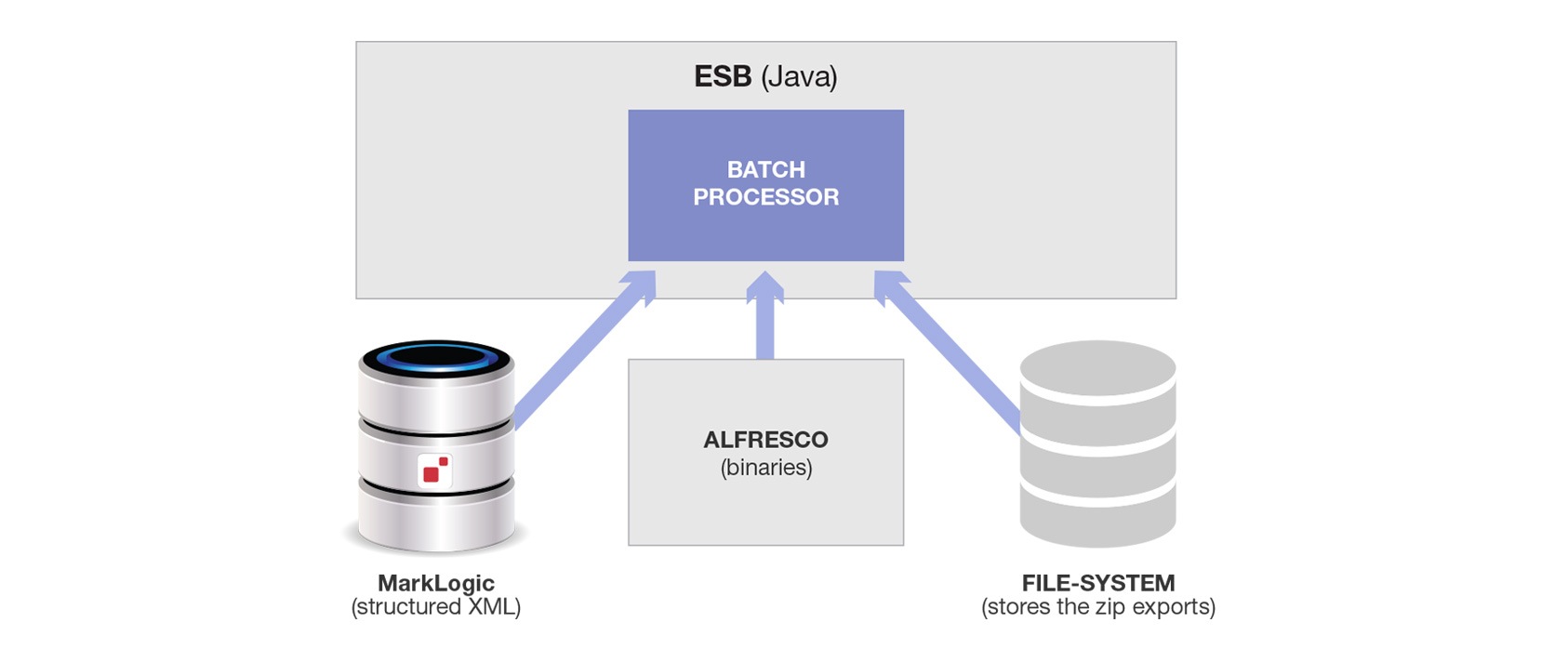
This diagram shows how a batch processor grabbed content from MarkLogic and wrote it to the file-system and also grabbed content from Alfresco and wrote that to the file-system. Both were zipped to limit the number of files in one directory (an alternative is to hash the filenames and use the first two digits of the hash to create 100 sub-directories of reasonable size. No free lunch – more complexity either way).
But recall there was a size limit on how much data could be moved and transferred. So we needed another post-process to determine file sizes on disk, and chunk the data into zip files with groups of matching XML and Zip files, totaling about 1GB each.
But wait, there’s more… The first Spring Batch process has to complete before the external python chunking script runs. So we need to connect both to a job scheduler (they used an enterprise Job Control product, but a cron job would do as well). Here is a diagram showing the additional components added to the overall architecture (new items circled in red):
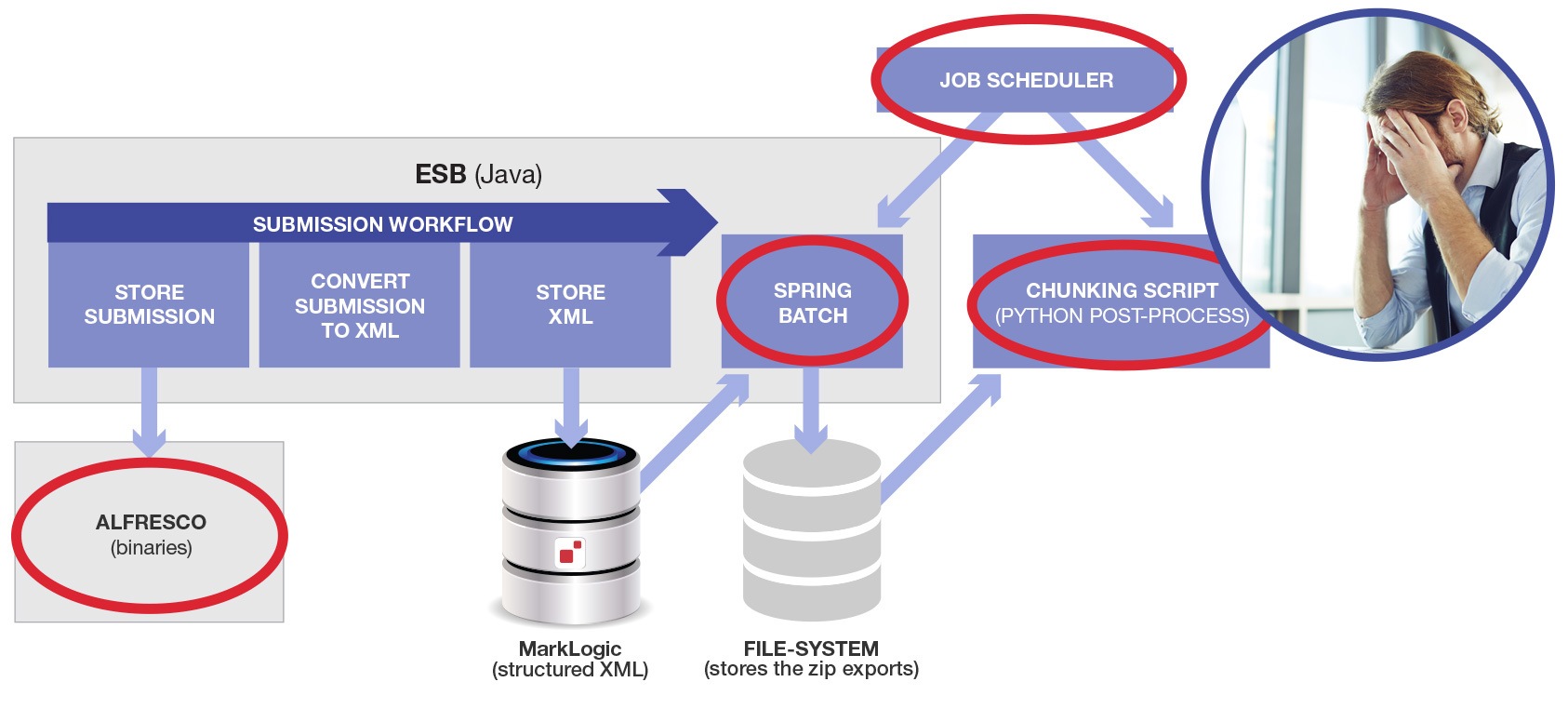
A lot more complex, isn’t it? My customer’s enthusiasm for the original solution was already waning.
Let’s Talk Physical Architecture
Alfresco uses two different stores, and does not manage transactions in them, much less XA transactions with other sub-systems; a relational database for some bookkeeping data and a file system for the actual binaries (because BLOBs don’t work well). For the file-system to be reliable we need a clustered, highly-available file-system like GlusterFS. Alfresco internally bundles a number of separate internal components with a core cobbled together from a relational database adapter and an internal build of Lucene for text indexing, plus direct file-system access. Here is an updated diagram with the internal physical and software components introduced by Alfresco:
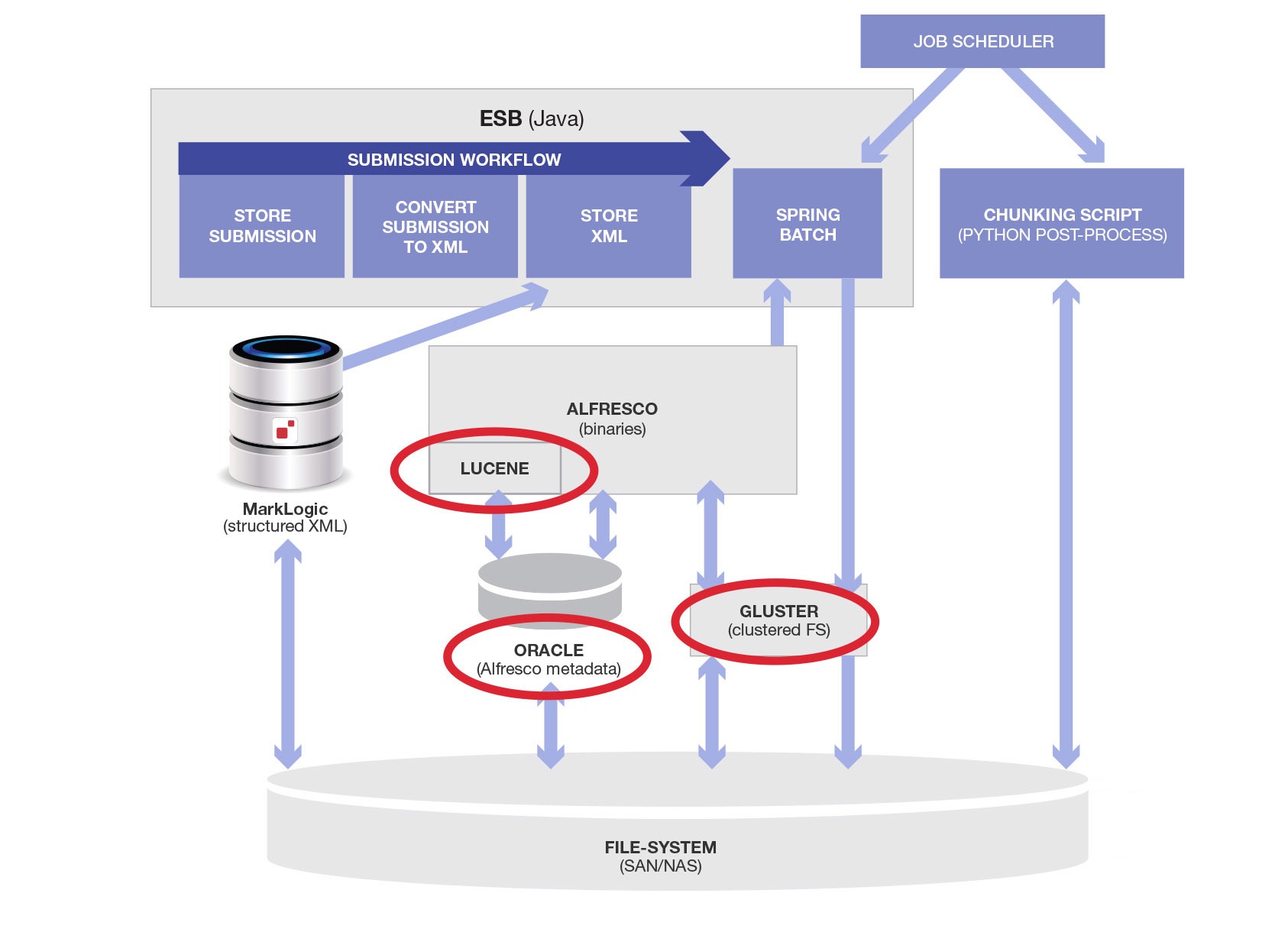
Remember the overall purpose or use case was “Not That Complicated!” We need to accept binaries and structured data, store it, and send it to a downstream system for verification! That’s it.
Operations
As those of you know who run enterprise software, every component in the infrastructure needs operations people and processes. This was a Highly-available (HA) system with Disaster Recovery (DR) requirements.
Disaster Recovery
DR basically means double everything, and configuring some process to constantly move all data to that duplicate infrastructure at a disaster site. MarkLogic was the primary database for the entire system and was replicated. Now that more components have been added to support Alfresco (Oracle, Alfresco, GlusterFS) they had to be configured to replicate so copies of their data were in the DR site at all times.
Is DR even possible with multiple stores?
To make matters (still) worse, we spent a lot of time considering how data would be kept in synch. Every sub-system replicates differently and with different time lags and “Recovery Point Objective” amounts of non-replicated data. When they all come up at the DR site, in the event of a disaster, they will be seconds or even minutes out of synch. We spend a surprising amount of time trying to add designs and governance about this. The time spent had a large opportunity cost – we should have been focused on other things but were distracted by managing data replication across multiple persistent stores.
High Availablilty
For HA, we needed to configure product-specific strategies for each major component (Alfresco Oracle/Lucene data, Alfresco binary file data, MarkLogic data).
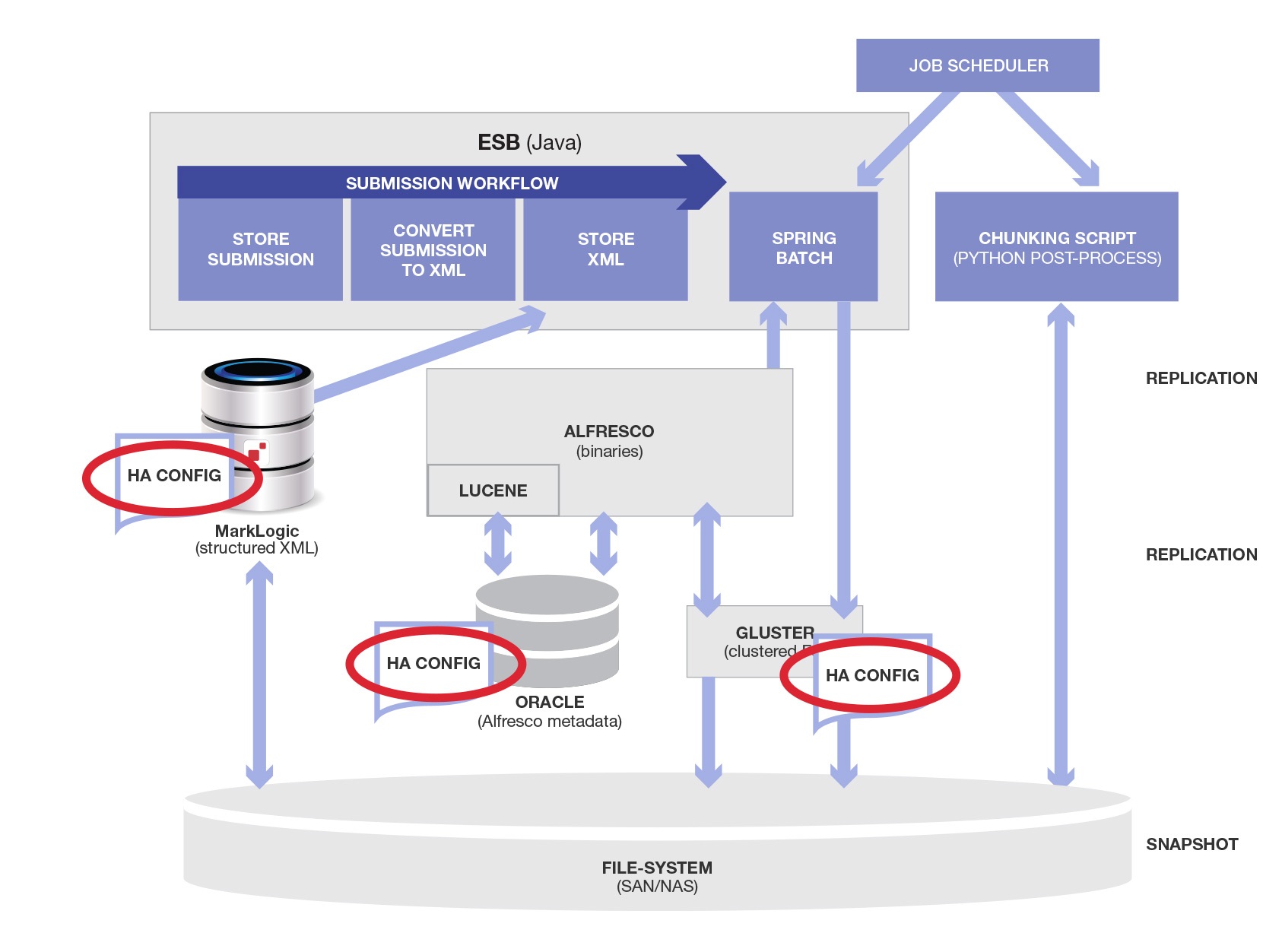
These “HA Config” boxes on the diagrams were worse than they look. They required duplicate infrastructure to be provisioned and configured for each of the (un-necessary) persistence technologies used. Each required meetings, vendor consultations, design documents and approvals. And testing. Separate High-Availability failover testing for each.
Process
Each of these needs its own trained staff, provisioned hardware, run-book (instructions for what do for normal operations as well as emergencies), test plans, upgrade plans, vendor or expert consultant relationships, and support contracts.
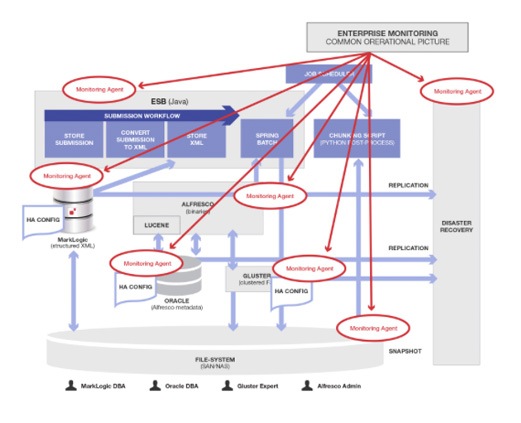
Here is the diagram showing the Disaster Recovery site and the data flows that need to be managed and configured. The new data flows are shown as red arrows, and the new people and roles are inside red circles:
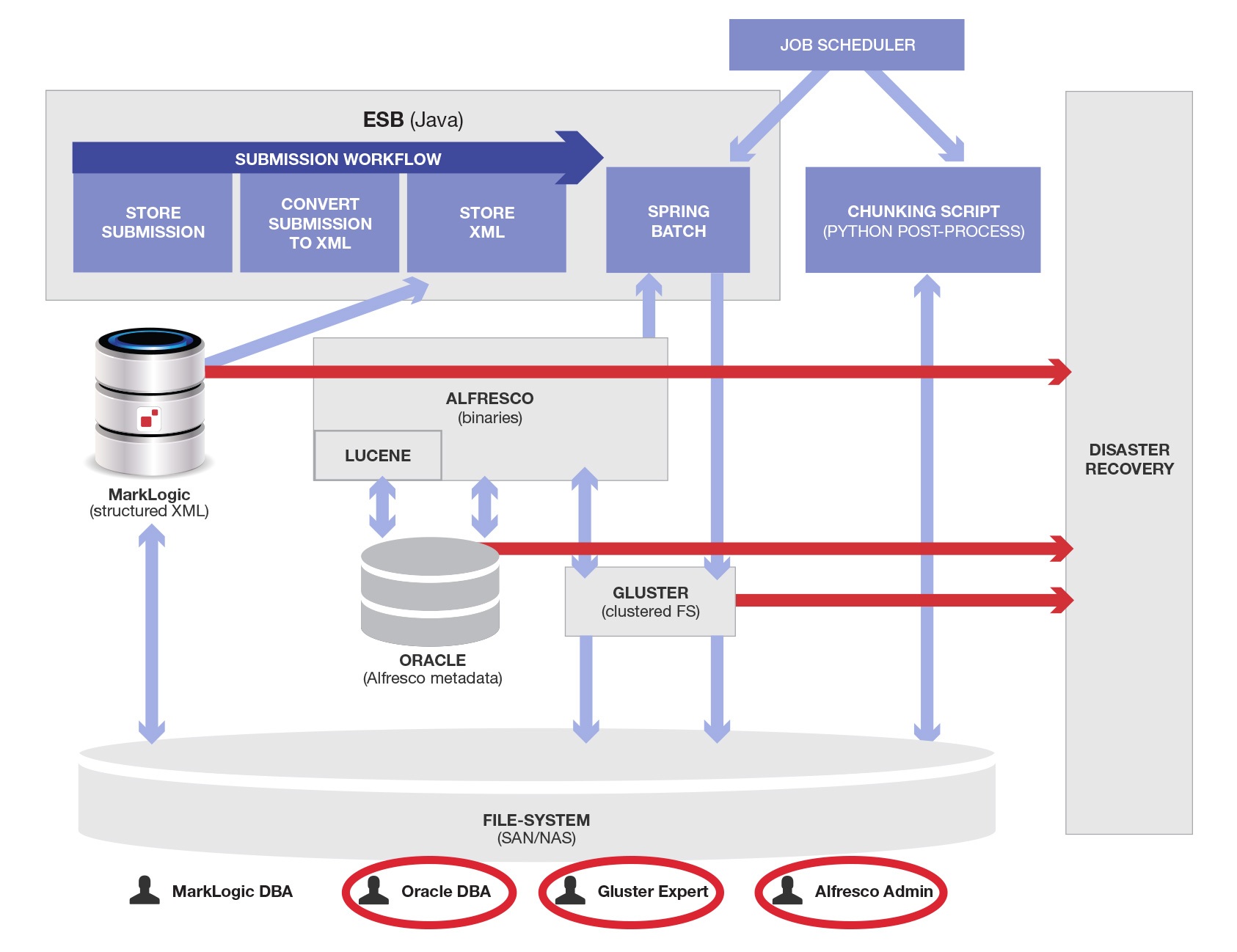
Unbelievable isn’t it? The people needed, processes needed, infrastructure needed, architectural components needed are not usually put on one diagram – for the very reason that humans can’t deal effectively with this level of complexity.
And it only gets worse.
Monitoring
I also spent many months stabilizing and improving another project – HealthCare.gov (Obamacare, as it is usually called). When it went live in poor shape, with bad performance and many errors, the White House sent in a group called the Ad-hoc Team to help fix it. The first thing they did when they came on the scene was buy and install monitoring at every level, in every component. You can’t run a critical enterprise system effectively without knowing what is happening inside your own system, and as experienced operations engineers, they prioritized monitoring at the top of the list.
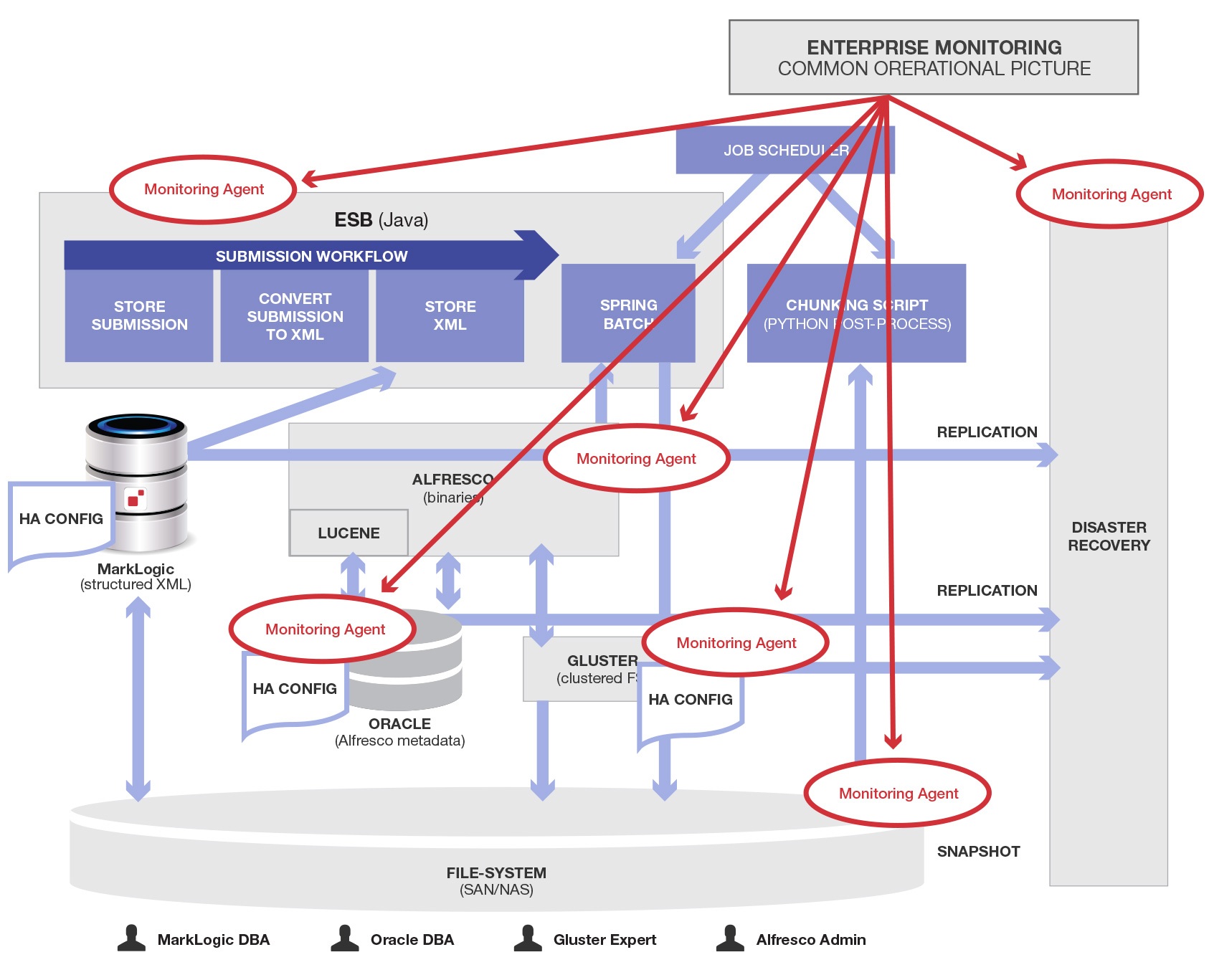
And our Mortgage Processing application described here also needs monitoring to work well. Unfortunately, by splitting data into multiple systems we had many more sub-systems to monitor. Products like the ones diagrammed so far often have APIs to help connect their internal monitoring and statistics feeds or logs to consolidated monitoring tools. Each of them needs to be monitored to form a common operating picture.
Again, here is a diagram with red circles to show the added monitoring agents that must be developed, maintained and integrated to keep all this stuff working that should not have been necessary. The Enterprise Monitoring product and MarkLogic agent are not circled, because they were going to be necessary even if the data was all stored in MarkLogic, as it should have been.
Deployment, Dev Ops, Automation
Each and every component requires some deployment, version control, testing. Those that have any code or customization must have that code integrated into the build. Experienced dear readers know that the overall maven/ant/gulp or similar system that knits all the components together into a known, testable and valid configuration are hugely complex. They are complex in part due to the number of components involved.
I will spare you another diagram, and just show the dev ops guy who has to build and maintain a pushbutton build with a Continuous Integration and Continuous Deployment capability:

How Not to Suffer Like We Did
So this is a fairly long, detailed story about how a simple requirement became an operational nightmare. I promise you your time has been better spent reading my history of what happened than if you had spent months or years living through it.
Everything (everything!) in the diagrams above is needed to run a system that does this simple submit, review and export task at scale in a mature, HA/DR, enterprise environment. It all started with a need to handle mortgage submissions, and a simple, naïve, dangerous mindset:
“Let’s use Alfresco to store the Excel and PDFs and put the XML in MarkLogic – that way we use a best-of-breed system for each type of data!”
Let’s look at what happens if we remove Alfresco and STORE THE #*&!%^!* DATA IN MARKLOGIC, AS THE PRODUCT WAS DESIGNED TO SUPPORT.
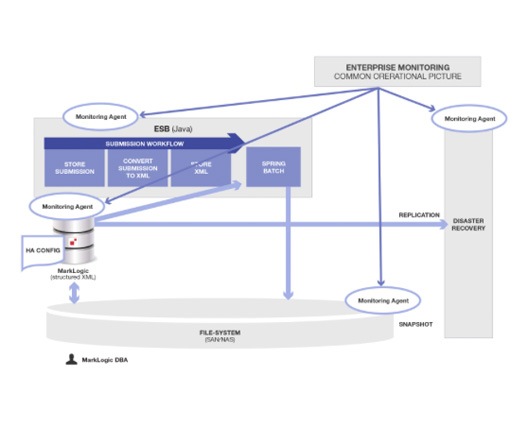
This one simplification is not a panacea. Operating an enterprise system is inherently complex and some of that complexity is fundamental complexity. Here is what we would have built and supported using MarkLogic to integrate and manage disparate data types together (binary and XML in this case):
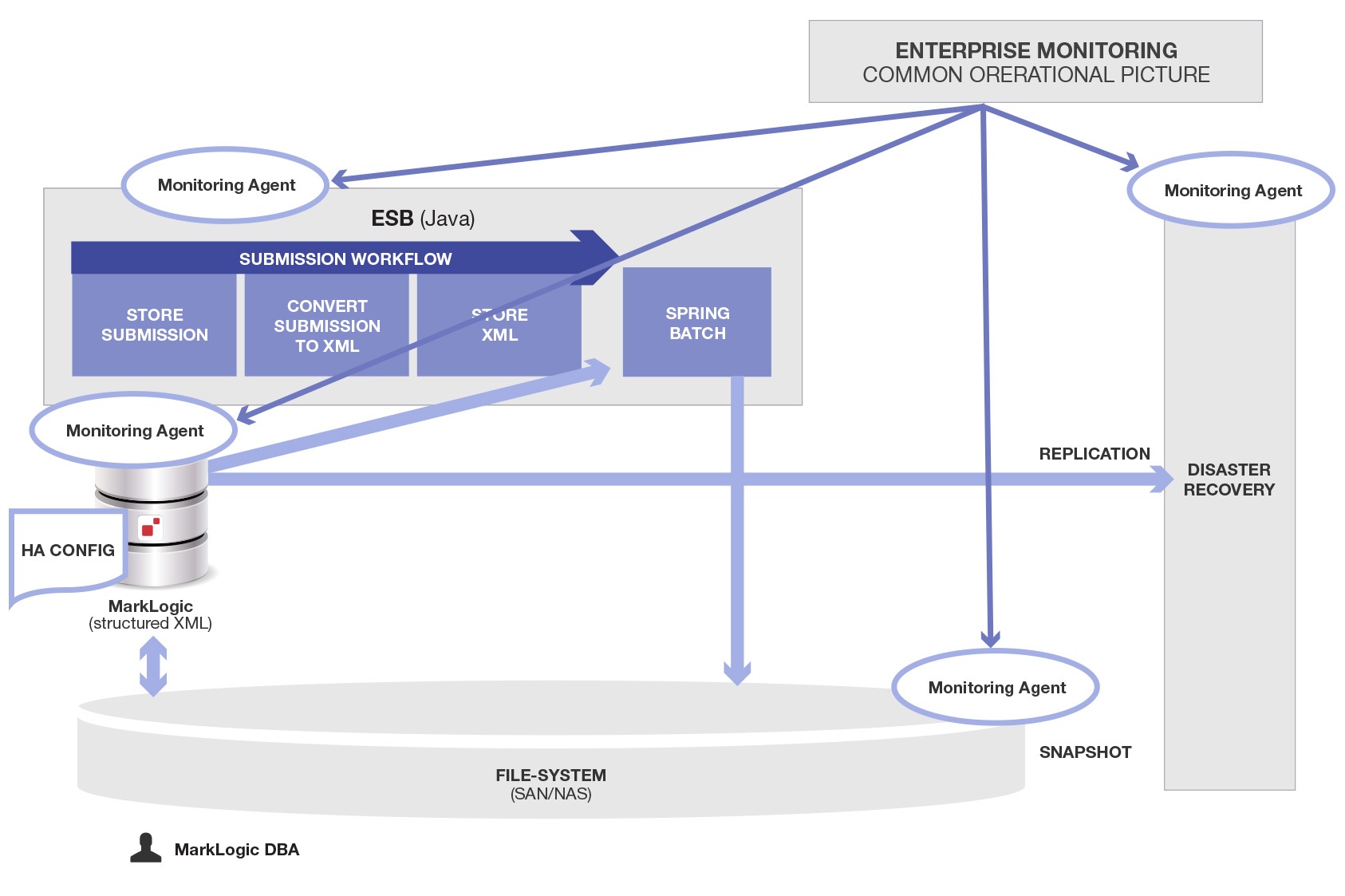
As we can see, reducing the number of components vastly simplifies the overall complexity and amount of work. This is not surprising, and we can consider it an axiom of software integration
“The complexity of a software integration project varies dramatically with the number of components that need to be integrated.”
The reason this diagram is so much simpler is because removing the extra data store (Alfresco in this case) removed all the integration, coordination, deployment, monitoring, configuration and supporting components that went with it.
The Right Answer
MarkLogic is specifically engineered to handle many types of data: XML, Binary, RDF, Text and JSON. The system will be far simpler (as we see above) if MarkLogic is used as an integrated, multi-model store that manages all the data together in one place.
By putting part of the data in one store (MarkLogic) and other parts of the data in another store (Alfresco) the system was vastly over-complicated. The additional complexity was hard to predict at the time, but it is obvious in hindsight.
The Big Picture
Here is where we ended up.
What they wanted to accomplish
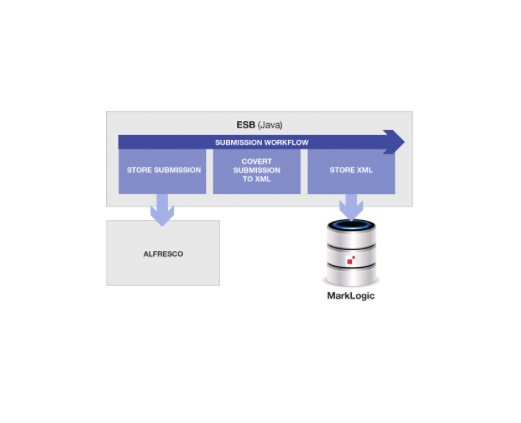
What they initially built
What MarkLogic did for them
MarkLogic Corp’s software development philosophy is rare. We use a single C++ core to solve the data management problem in one place, cutting across many data types from Text to RDF and XML to Binary. Most others deliver a “solution” that hides an amalgam of open-source or acquired separate components, which masks and increases complexity rather than eliminating it.
Put another way, MarkLogic database achieves the goal of Polyglot Persistence via the technique of multi-model storage. With MarkLogic you get Polyglot persistence without “poly lot” of headaches.
But the “philosophy” above is abstract and it is hard to know why it matters without living through concrete implementations. The example recounted above is real. It was not really Mortgages, but all the integrations and impacts actually happened, and you can avoid the frustration that I experienced – and more importantly deliver value to your users and customers without being distracted by myriad integration headaches that really don’t need to happen in the first place.

Damon Feldman
Damon is a passionate “Mark-Logician,” having been with the company for over 7 years as it has evolved into the company it is today. He has worked on or led some of the largest MarkLogic projects for customers ranging from the US Intelligence Community to HealthCare.gov to private insurance companies.
Prior to joining MarkLogic, Damon held positions spanning product development for multiple startups, founding of one startup, consulting for a semantic technology company, and leading the architecture for the IMSMA humanitarian landmine remediation and tracking system.
He holds a BA in Mathematics from the University of Chicago and a Ph.D. in Computer Science from Tulane University.
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Secure File Transfer
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites